개요
- GPT 계열의 모델 발전은 학습 데이터의 양과 컴퓨팅 자원의 증가가 주요하였음 (최근 GPT-3.5—ChatGPT까지도)
- 특히 GPT-3부터는 놀라운 성능임에도 불구하고 model parameter수가 급증함(175B)에 따라 컴퓨팅 자원이 받쳐주지 않는 이상 이용이 불가한 수준임
- 게다가, OpenAI에서 GPT-3모델을 공개하지 않고, 데모와 API를 통해서만 제공함
- 이에, 오픈소스 연구단체인 Eleuther AI는 GPT-3의 오픈소스 버전인 GPT-Neo와 GPT-J를 공개함 (학습 및 테스트 데이터셋—The Pile 데이터셋—및 코드를 공개)
- 두 모델 모두 Huggingface에서 지원하고 있음
GPT-Neo
- mesh-tensorflow를 이용한 모델 → Huggingface에서는 PyTorch와 Deepspeed로 이용가능
- 모델 크기에 따라 GPT-Neo 125M, 350M, 1.3B, 2.7B 총 네 가지 버전이 있음
- GPT-3와 같은 기능을 수행함과 동시에, 무거운 모델을 해결하기 위해 아래와 같은 방법론들을 사용함
- Local attention
- Linear attention
- Mixture of Experts (MoE network)
- Axial Positional embedding
위 방법론을 하나씩 살펴보자.
1. Local attention
Longformer: The Long-Document Transformer
Longformer: The Long-Document Transformer
Transformer-based models are unable to process long sequences due to their self-attention operation, which scales quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention mechanism that scales linear
arxiv.org
<Summary>
- Transformer의 self-attention (quadratically) computational cost를 줄이고, 이를 통해 보다 긴 sequence의 context를 이해하도록 함
- Window slinding을 통해 전체를 local로 쪼개어 attention하는 방법임 (CNN에서 image를 한번에 다 보는 것이 아니라 kernel로 windowing하듯)
Attention Patterns

1. 1 개요
- Self-attention은 sequence length, n에 따라 계산량이 quadratical하게 증가함
- 이를 줄이기 위해, self-attention을 attention pattern에 따라 sparse하게 만들었고, 결국 n에 linear하게 증가되도록 계산량을 개선함
- 여기서 attention pattern이 의미하는 바는, 각 input 위치와 그 영향을 받는 다른 위치에 따라 attention이 걸리는 부분에 따라 여러가지 pattern처럼 보이는 것을 말함
1. 2 Attention patterns
(1) Sliding window
- fixed-size의 window attention을 수행 (self-attention with window size라고 생각해도 무방함─CNN처럼)
- 만약, multiple windowed attention을 stack하면 모든 location attention을 구할 수도 있음
(2) Dilated sliding window
- computational을 늘리지 않고 receptice field를 늘리는 방법이 바로 "dilated"시키는 것
- 즉, window에 gap, dilation size d를 만들어 확장시키는 것임
- multi-head attention의 각 head마다 다른 dilation configuration─사이즈를 다르게 주거나(d=1, 2, 3) 안 주거나(d=0)─을 주면 성능이 더욱 향상됨을 확인
- dilation이 없는 head는 local context를 보고 dilation이 있는(혹은 큰) head는 longer context를 보고 이를 합치기 때문임
(3) Global attention
- Windowed attention과 dilated attention은 task-specific representation을 배우기에는 어려웠음 (not flexible)
- 이에, pre-selected input location에 대한 정보를 주는 방법을 고안함 → 이게 global attention
- 이 global attention은 symmetric하게 부여되었고, 모든 input token에 부여되도록 함

Gloabl attention 예시 - 노란색이 gloabal attention. 다른 attention pattern들(sliding. dilated)에 비해 각 가로, 세로 끝까지 부여된 것을 알 수 있음
- 예를 들면, QA task에서 Question에 해당하는 token에 global attention을 줄 수도 있음
2. Linear attention
Efficient Attention: Attention with Linear Complexities (WACV 2021)
Efficient Attention: Attention with Linear Complexities
Dot-product attention has wide applications in computer vision and natural language processing. However, its memory and computational costs grow quadratically with the input size. Such growth prohibits its application on high-resolution inputs. To remedy t
arxiv.org
<Summary>
- input size가 커짐에 따라 memory, computational cost가 커짐을 해결
- Attention에서 Query와 Key를 내적하는 과정에서 Q, K의 dimension에 비례하여 증가하는 computational cost, O(n2)를 회피하는 방법을 제안함
2. 1 (Revisit) Attention
- Attention이란, Seq2Seq모델에서 decoding할 시 input을 한 번 더 참고하고자 고안된 알고리즘임
- 구체적으로는, decoder의 t시점에서 전체 input의 hidden state에서 집중해야 할 부분은 weight함
- Attention Process
| Step | Description |
| ① Attention score 계산 | t시점의 decoder hidden state와 모든 시점의 encoder hidden state를 내적 |
| ② Attention distribution화 | 위 score에 softmax함수를 취하여 sum to 1으로 분포화시킴 |
| ③ Attention value 계산 | attention distribution값을 기반으로 모든 시점의 encoder hidden state와 곱하여 weighted sum (t시점의 attention score) |
| ④ Concatenate | t시점의 decoder hidden state와 단순 concat |
| ⑤ Weight, Bias parameterize |
학습가능한 weight과 bias, activation function(tanh)을 통해 parameterize하고 학습 |
| ⑥ 최종 output | 위 parameterize한 결과를 통해 output layer에서 argmax하여 output을 출력함 |
- Query, Key, Value
- Query : t시점에 decoder의 hidden state
- Key : 모든 시점에서 encoder의 hidden states
- Value : 모든 시점에서 encoder의 hidden states (key와 mapping되어 있는 값이라는 뜻이긴 하나, 결국 key와 같음)
- 주어진 Query에 대하여 모든 Key와의 유사도를 구하고 유사도가 반영된 값(Value)를 모두 더하여 return함
- self-attention에서는 Q=K=V로 시작함 (학습동안 달라짐)
2. 2 Dot-Product Attention (=Attention)
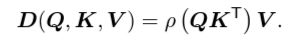
- ρ는 normalizing function (scaling을 하거나 softmax를 취함)
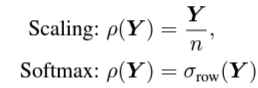
- scaling을 하는 이유는 Q, K의 차원이 커짐에 따라 attention score도 비례하여 커지기 때문에 모델 학습에 어려움이 생김 (모델 weight보다도 커짐)
2. 3 Efficient Attention
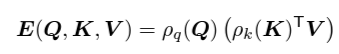
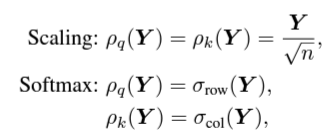
- efficient attention은 위와 같은 구조로 바꾸어 Dot-Product Attention과 같은 계산 결과를 가지면서 computational cost를 줄인 방법임
- 아래 그림을 참고하면, Q와 K를 내적해야하는 과정에서 pairwise similarity를 계산해야하는 cost를 회피하기 위하여 고안하였음

Dot-Product Attention과 Efficient Attention - 수식적으로 봐도 Q와 K를 내적하지 않고 K와 V를 먼저 내적하고 곱한 것을 알 수 있음
3. Mixture of Experts (MoE)
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (ICLR 2017)
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
The capacity of a neural network to absorb information is limited by its number of parameters. Conditional computation, where parts of the network are active on a per-example basis, has been proposed in theory as a way of dramatically increasing model capa
arxiv.org
<Summary>
- Deep Learning의 도래 이후, 모델 학습 파라미터 수(=모델 크기)에 비례하여 성능이 향상됨
- 물론 그에 맞게 데이터셋 증가와 학습 파라미터들을 tuning해주어야 함
- 이에, training cost를 줄이고자 conditional computation하는 방법들이 고안되기 시작함 (dropout)
- Mixture of Experts layer (MoE)는 Expert라고 불리는, 그 자체로 neural network이면서 학습가능한 parameter를 지닌 network를 여러 개 component로 둔 network임
MoE layer
- Gating network를 통해 학습 Expert를 고르고 해당 Expert network만 학습함(=Conditional computation)

4. Axial Positional Embedding
Axial Attention in Multidimensional Transformers
Axial Attention in Multidimensional Transformers
We propose Axial Transformers, a self-attention-based autoregressive model for images and other data organized as high dimensional tensors. Existing autoregressive models either suffer from excessively large computational resource requirements for high dim
arxiv.org
<Summary>
- 앞선 section의 efficient attention에서도 문제 제기하였듯이 transformer의 self-attention에서는 어마어마한 연산량이 필요함
- 특히, Query와 Key의 pairwise similarities를 계산하는 부분에서 O(n2)의 연산량이 요구됨
- high-dimensional data (image, video)에서는 이러한 연산량이 매우매우 치명적임
- 그러한 원인 중 하나가 self-attention을 flatten시켜서 구하게 되는데, 이 것에 문제를 제기함 (32 x 32 x 3 이미지 간의 self-attention → 30722
- 이에, tensor를 flatten시키지 않고 tensor의 축 별로 attention시켜 연산량을 줄이고자 함(그래서 "axial" attention)
- flatten을 시키지 않고 축을 row방향이든 col방향이든 축 방향으로만 attention을 수행하면 computation이 줄 수 밖에 없음 (d = r × c일때, d >> r or c이므로)
- 예를 들어, tensor shape이 N= N1/d × ... × N1/d이라면, O(N(d-1)/d)만큼 줄일 수 있음
- 계산량을 줄이는 대신, 모든 context정보를 담을 수 있게 설계함

4. 1 Self-attention의 limitation과 Related works
- (Revisit) Self-attention
- 수식 (Q: query, K: key, V: value, A: attention score matrix)

- 일반 attention과 수식은 같으나, 차이점은 초기 값이 Q=K=V로 설정된다는 것
- 결국, sequence X로부터 attention score가 반영된 Y를 구하는 것이 목적인데, 이 과정에서 Query, Key의 외적에서 "O(n2)"의 시간복잡도가 발생함
- 수식 (Q: query, K: key, V: value, A: attention score matrix)
- Related works
- 크게 두 가지 strategy가 존재함
- 한번에 처리하는 data량을 줄이는 방법 (n을 줄임) → X대신 Xsmall을 사용하는 방법
- X는 full로 사용하되 sparse한 attention layer를 여러 개 두어 계산량을 줄인 후 stacking하는 방법 → W을 sparse하게 하는 방법
- 하지만, 각 방법론마다 한계가 명확함
- 첫 번째 strategy (Xsmall)
- Small subset을 사용하지만, full joint distribution을 이용 못하는 것 = full-context를 이용하지 못함
- 연산 과정에서 redundant data copies가 발생함 → small subset을 활용하는 window를 extract하고 processing하는 과정 중
- 두 번째 strategy (sparse W)
- 사용하는 hardware자원에 한정된 archtecture만 사용할 수 있음 (GPU - matrix matrix multiply인데, TPU에서는 이를 활용 못한다)
- 이는 곧, 이미지 데이터에서만 최상의 성능을 낼 수 있는 한계가 있음 (The strided sparse transformer)
- 첫 번째 strategy (Xsmall)
- 크게 두 가지 strategy가 존재함
4. 2 Axial attention
- 일반(standard) attention과 다르게, 축 방향으로만 attention하는 방법
- 이미지에서는 column attention 과 row attention이 존재함
- Masked attention : input과 output의 component가 서로에게만 영향을 미침
- 논문 발췌(직역) : MaskedAttentionk(x)의 result의 component i는 x의 component i에만 의존한다.
- 구조(=Residual axial attention)
- FeedforwardBlock(x) = x + DenseD(Nonlinearity(DenseD'(LayerNorm(x)))
- AttentionBlockk(x) = x + DenseD(Attentionk(LayerNorm(x)))
- TransformerBlockk(x) = FeedforwordBlock(AttentionBlockk(x))
GPT-J
- Mesh Transformer Jax기반 (TPU모델) - 그래서 J
- 이전 GPT-Neo에서 학습한 The Pile 데이터셋으로 동일하게 학습함



