본 포스팅은 Leveraging Pre-trained Checkpoints for Sequence Generation Task 논문의 리뷰를 다루고 있습니다.
개인적 고찰은 파란색으로 작성하였습니다. 해당 내용에 대한 토론을 환영합니다 :)
Background
- BERT와 같은 pre-trained model은 Natural Language Understanding(NLU) 분야에서는 괄목할만한 성과를 달성하였지만, sequence generation과 같은 decoder-based task에 대해서는 큰 효과를 보이지 못함
- 이러한 흐름에서, BERT-NMT와 같은 machine translation에 특화된 구조를 채태하는 논문도 같은 시기에 등장하였고, 이에 본 논문도 같은 흐름으로 연구되었다고 생각함
- Generation task를 수행하기 위해서, encoder-decoder구조를 채택하게 됨 → transformer의 어느 한 쪽 module을 사용하는 것보다 generation task를 위해서 (encoder 입장에서는 더 나은 generation을 위해서, decoder는 generation 자체를 위해서) encoder-decoder구조가 필요해짐
- Unsupervised learningrhk self-supervised learning 기반 pre-trained_model(ELMo, ULMFiT, BERT, GPT, GPT-2 등)이 연구되면서 NLU benchmark dataset에 대해서 많은 성과를 달성하였으나 이런 모델을 seq2seq model에 적용하는 것에는 비중있게 다뤄지지 않았음
- 본 논문에서는 large collections of text로 pre-training된 large model이 seq2seq generation model로써의 beneficial함에 대한 의문을 검증하는 것을 목표로 함
- 궁극적으로는 다음의 question에 대해 empirical answer를 내리는 것
💡 Key Question of this paper
What is the best way to leveraging publicly available pre-trained checkpoints for warm-starting sequence generation models?
- 조금 더 task-based로 이야기하자면, 공개된 pre-trained model의 checkpoints들을 encoder-decoder transformer model의 model parameter의 initializer로 이용하여 sequence generation task를 수행해보겠다는 것
- 논문에서 든 예로, "보다 나은 text generation을 위해서 BERT checkpoints를 encoder initializer로써 싸용하고, GPT-2 model을 decoder로 사용하는 것을 상상해볼 수 있다."고 함 → 논문이 하고자하는 바를 명확히 설명하는 예
- 수행한 generation task는 다음과 같음
- Sentence Fusion
- Sentence Split and Rephrase
- Machine Translation
- Abstractive summarization
- 결론적으로, randomly initialized model들보다 좋은 성능을 달성함
- (중요) 또한 pre-trained encoder가 sequence generation task에 중요한 역할을 함 → encoder-decoder의 weight share가 큰 이점으로도 작용
- Sequential modeling을 위해서 Well-trained BERT가 관건
Method (Model)
- Encoder-Decoder architecture를 사용
- Encoder는 BERT Transformer layer
- Decoder는 BERT를 이용하였지만 2가지 변경사항이 있음
- Self-attention을 left context에만 masking하여 사용
- Encoder-Decoder attention을 이용함
- Model이 randomly initialized되었다면, BERT 호환 decoder와 GPT-2 호환 decoder의 성능이 큰 차이가 없음 (noticable)
- 여러 Pre-trained model의 base checkpoint와 best checkpoint의 비교
- Model들은 target task에 대해 fine-tuned
- Optimizer : Adam
- Learning rate : 0.05 with a linear warmup with 40k steps and inverse sqrt decay
- Layer Normalization (by sqrt of hidden size)
| 구분 | Base Checkpoint | Best Checkpoint |
| # of Layers (NUM_LAYERS) | 12 | 24 |
| Hidden size (EMBED_DIM) | 768 | 1024 |
| Filter size (FF_DIM) | 3072 | 4096 |
| Attention heads (NUM_HEDAS) | 12 | 16 |
- BERT checkpoints (https://github.com/google-research/bert)
- Tokenizer : WordPiece
- BERT-base-cased (vocab size : ~30k)
- BERT-base-uncased (vocab size : ~30k)
- BERT-base-multilingual-cased (vocab size : ~110k)
- Positional Embedding size : 512
- GPT-2 checkpoints (https://github.com/openai/gpt-2)
- Tokenizer : SentencePiece (max_len = 512)
- 117 M (# of model parameters가 가장 작은 모델)
- BERT-base-cased와 동일한 layer 수, hidden size, filter size (NUM_LAYERS, EMBED_DIM, FF_DIM)
- Vocab size : ~50k
- Positional Embedding size : 512 (Original GPT-2는 1024)
- RoBERTa checkpoints (https://github.com/facebookresearch/fairseq)
- PyTorch로 구성, some minor adjustment를 통해 Tensorflow BERT와 호환가능
- 변수명 align
- Weight/Bias parameters → Key, Query, Values로 split
- Embedding matric을 제외하고 Transposed
- BERT와의 concept 자체가 크게 다르지 않음
- PyTorch로 구성, some minor adjustment를 통해 Tensorflow BERT와 호환가능
Model Variants
- 모델 이름의 구성은 "enc_model"-2-"dec_model"의 형식으로 구성되어 있음
- Base model은 encoder-decoder구조의 transformer이며, 각 부분에 model명을 사용한 것이 해당 모델로 intializing했다는 것을 의미함. ex) BERT2BERT → a BERT-initialized encoder & a BERT-initialized decoder
- Model components
- RND : randomly initialized model (구조는 transformer)
- SHARE : encoder와 decoder의 parameter가 shared
- 그 외에는 Model명을 그대로 사용
- 사용된 모델 조합과 # of total trainable parameters (total), embedding parameters (embed.), parameters from checkpoint (init.)

Experiments
- Sentence Fusion
- 해당 Task는 여러 개의 문장을 단 하나의 문장으로 결합하는 것
- Dataset : DiscoFuse (4.5M for training, 50k for evaluation)
- Evaluation metric : SARI (ref: https://cocoxu.github.io/publications/tacl2016-smt-simplification.pdf)
- Predicted simplified sentence를 reference와 source sentence와 비교하여 얼마나 잘 simplified되었는지 판단
- Model에 의해 added, deleted, kept words의 goodness를 측정
$$ SARI = d_1 F_{add} + d_2 F_{keep} + d_3 P_{del}$$- $F_{add}$

-
-
-
- $F_{keep}$
-
-

-
-
-
- $P_{del}$
-
-

-
-
- Result
-

-
-
- 전체 training dataset의 10%만 사용해도 baseline의 performance와 comparable한 결과를 얻음
- 1% 실험결과에서 BERT2BERT (81.2) vs BERT2RND (80.3)의 결과로 미루어보아, randomly initialized parameter를 적게 사용한 것이 더 좋은 performance를 보임
- 이는 encoder부분에서 더 두드러지는 차이를 보임. RND2BERT (72.8) vs BERT2BERT (81.2)
-
-
- Sentence Split and Rephrase
- Task 자체는 Sentence fusion의 reversed task임
- 즉, long sentence를 2개 이상의 short sentence로 rewrite
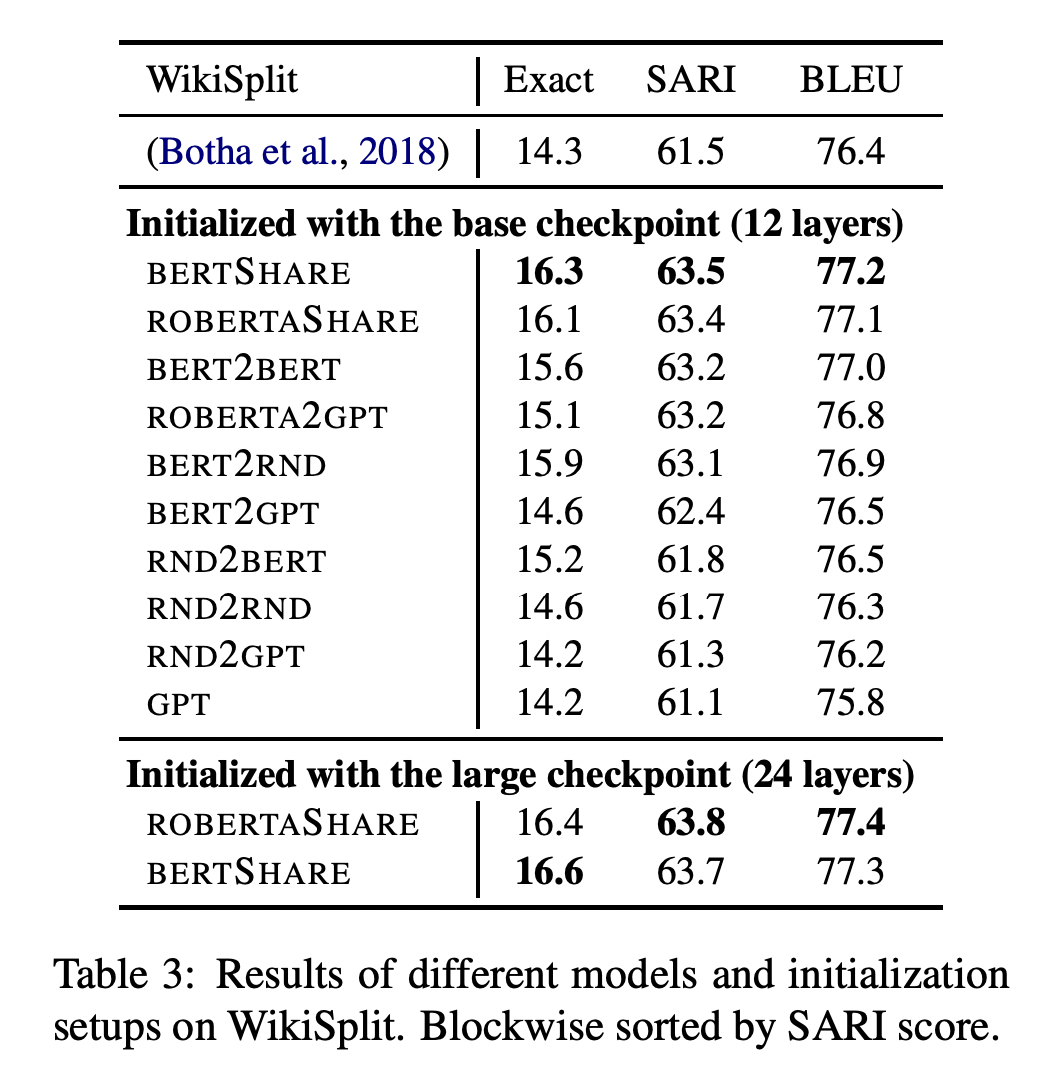
- Dataset : WikiSplit (1M, extracted from Wikipedia edit history)
- I/O data는 128 length로 padding
- Evaluation metric : The Exact Match accuracy, BLEU, SARI
- BLEU (Bilingual Evaluation Understudy) : n-gram기반 기계번역 성능 측정 measure
- Result
- Large model(24 lyrs-BERTSHARE, ROBERTASHARE)이 더 좋은 성능을 보이는 경향이 있으나, 같은 epoch을 주면 더 일찍 overfitting됨. (early stopping)
- Task 자체는 Sentence fusion의 reversed task임
- Sentence Split and Rephrase
-
- Machine Translation
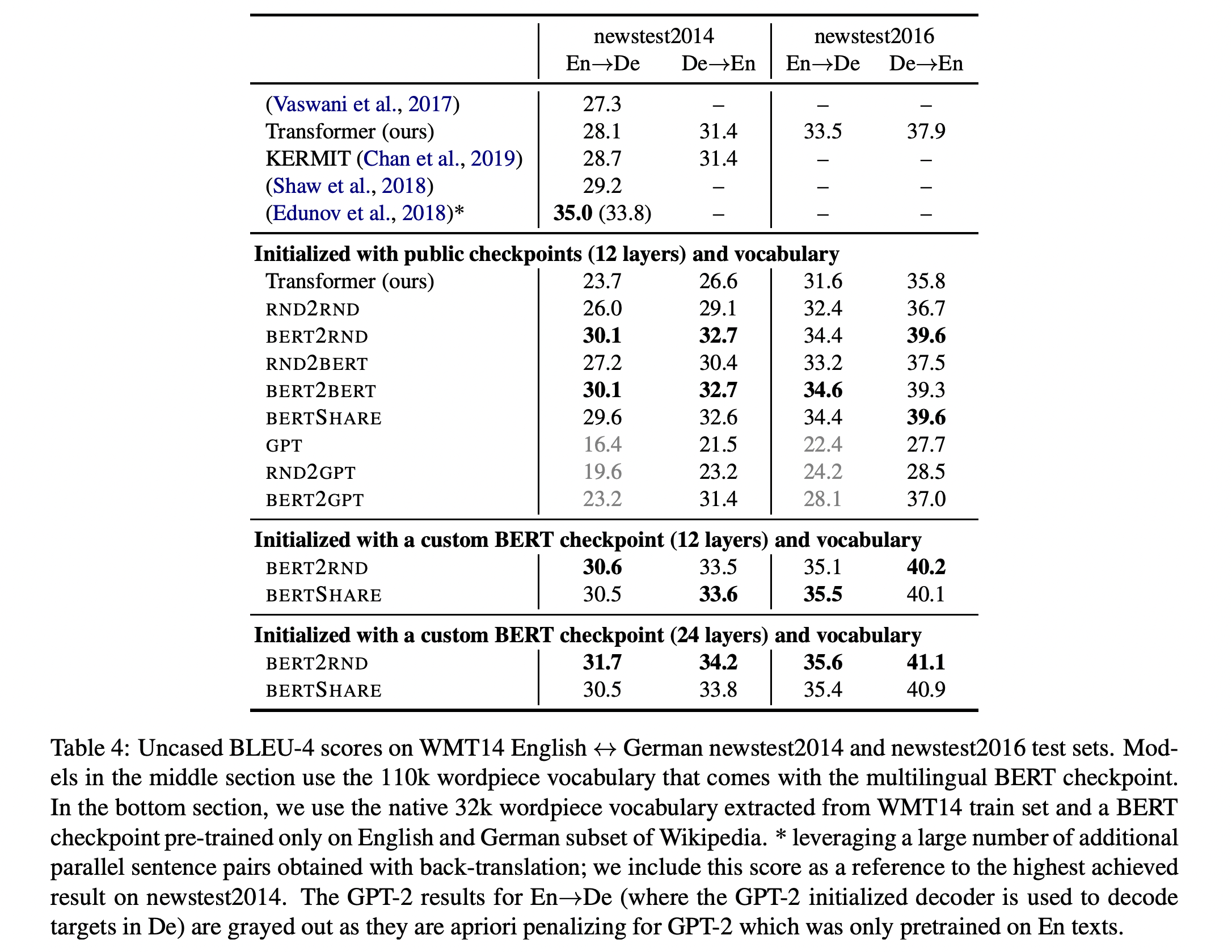
- WMT 2014 English $\leftrightarrow$ German 번역 task를 수행
- Dataset : newstest2014, newstest2016
- Result
-
- 1st row result
- (Vaswani et el., 2017)은 original transformer, Transformer(ours) (이하 ours)는 BERT의 layer를 이용하여 transformer구조를 재구성
- Vocab : 32k (WordPiece)
- BERT layer를 이용한 ours가 original transformer보다 근소하게 좋다
- (Vaswani et el., 2017)은 original transformer, Transformer(ours) (이하 ours)는 BERT의 layer를 이용하여 transformer구조를 재구성
- 2nd row result
- (BERT) Encoder에서 BERT-initializing의 효과가 두드러짐
- BERT의 checkpoint는 BERT-base-multilingual-cased를 이용 (108개의 언어, 110k의 WordPiece vocab)
- BERT2RND와 RND2RND의 performance를 비교하면 두드러지게 확인할 수 있음
- Sentence fusion, split and rephrase와는 다르게, SHARE model의 효용이 떨어짐
- model capacity가 MT에서는 중요한 facter → 하나의 언어만을 다루는 fusion, split, rephrase와는 다르게 두 가지 이상의 언어를 다루는 MT model은 그만큼 많은 weight parameter들을 이용해야한다고 해석
- encoder, decoder가 다른 grammer와 vocabulary를 가짐 → 위 해석과 맞물려, encoder, decoder와 각각 다루는 언어가 다르기에 weight이 달라야 reasonable하다는 뜻으로 해석
- 즉, encoder-decoder의 weight SHARE model은 model 경량화의 이점이 있 지만, MT와 같은 다른 domain사이의 mapping task에서는 각기 다른 weight space와 weight parameter들을 가져야함
- (GPT) 반면에, decoder에서 GPT-initializing의 효과는 미미함(미미하기보다는 do not perform수준)
- 특히, Target language가 German일 때 decoder로서의 GPT가 do not perform
- 이는 GPT가 주로 English text로 pre-training한 모델이기 때문 → 이러한 이유로 En-to-De의 GPT 실험결과는 모두 gray처리함
- 같은 pre-trained model임에도 BERT의 경우 multilingual로 pre-training하였기때문에 극명한 차이가 발생했다고 생각함
- 결국 pre-trained model도 domain의 영역에 많은 영향을 받는다
- GPT-2가 지향하는 zero-shot은 결국 domain내에서의 task의 관점 → unseen data (특히, domain자체가 바뀐 data)에 취약함
- (BERT) Encoder에서 BERT-initializing의 효과가 두드러짐
- 3rd~ row result
- 해당 실험은 custom BERT checpoint를 이용한 실험임
- 전체 실험에서보면 RoBERTa를 이용하지 않음 → English only checkpoint이기때문 (English decoder로도 이용가능할 수도 있을텐데, 아마 앞선 GPT 실험결과로 얻은 교훈때문이지 않을까 싶음)
- 또한, Original transformer (6 layer, 32k wordpiece)에 비해 ours와 RND2RND이 newstest2014 dataset에 weak performance를 보임
- 이러한 차이에 대해서 본 논문의 저자는 다음과 같은 가설을 세움
- (BERT의 checkpoint로 BERT-base-multilingual-cased를 이용하였기때문에) 110k나 되는 vocab size와 104개의 language가 WMT14 data에 suboptimal이다.
- Theoretical backup이 없는 가정사항이라 명확하지 않지만, 위 conjection을 곱씹어보면, 2개의 언어만 다루는 MT task는 104~8개나 되는 multilingual관점에서는 scope이 더 적다(suboptimal)는 뜻으로 사료됨
- 그리하여 WMT 14 En $\leftrightarrow$ De dataset에 대해 32k로 vocab size를 맞추고 BERT model을 pre-train하였음 (BERT-base-multilingual-cased를 training하는 것처럼) → 이것이 custom BERT checkpoint
- 1st row result
-
- Abstractive summarization
- Sentence fusion에 비해 더 큰 차원의 summary를 수행함
- Document단의 summarization (while preserving its salient information content)
- 하지만, 아래 Giga-word dataset을 보면 sentence summary도 수행함
- Dataset
- Gigaword (3.8M, sentence-summary pair)
- CNN and DailyMail (287k, document-summary pair)
- BBC extreme (204k, document-single sentence summary pair)
- CNN and DailyMaildms multiple sentence로 요약하는 반면 BBC extreme dataset은 single sentence로 요약 → 더 high level의 abstractiveness
- Result
- Document understanding
- BERT encoder가 모두 RND2RND model을 큰 차이로 outperform
- RND2BERT만이 BERT encoder를 사용한 model과 유일하게 비슷함
- 전반적으로 encoder-decoder 구조에서 document reperesentation이 summarization task에 중요한 역할을 함
- 이러한 효과는 BBC extreme dataset과 같은 high level abstraction을 요구하는 task에 대해서 더 큰 효용을 증명함
- 아마도 BBC dataset 자체는 document 내의 모든 sentence가 동일한 distribution을 따른다고 볼 수 있는 것에 반해 다른 dataset들은 그렇지 않은 sentence가 존재함 e.g.) Gigaword의 headline이나 CNN/DailyMail의 bullet-point로 된 sentence들
- BERT encoder가 모두 RND2RND model을 큰 차이로 outperform
- Summarization with GPT checkpoints
- 주목할 것은 GPT(only)가 RND2GPT, BERT2GPT, RoBERTa2GPT와 같은 encoder를 붙인 모델들의 성능을 모두 outperform하였다는 것임 (CNN and DailyMail dataset한정)
- 그러나, BBC dataset에서는 그렇지 못하였음
- 이러한 실험결과를 통해, encoder-decoder구조가 decoder-only구조보다 document abstraction에 더 좋은 성능을 보인다는 것을 증명함
- encoder-decoder구조는 input document가 분리되서 모델링되고, decoder-only구조는 input document가 language model의 conditioning prefix이기때문
- 결국 document abstraction의 경우 encoder-decoder구조가 더 잘 working한다는 것인데,, 이 경우 architecture의 승리라기보다는 dataset이 BBC dataset이 summary하기 더 nice하기 때문이라고 생각함
- 정리하자면,
- CNN and DailyMail과 같이 한 document 내의 sentence들이 동일한 distribution을 따르지 않음 (multi-modal) → GPT only model이 더 좋음
- BBC dataset의 경우, 한 document 내의 sentence들이 동일한 distribution을 따름 (uni-modal) → encoder를 붙이는 것이 더 좋음
- 이를 통해서 BERT encoder 혹은 encoder-decoder 구조에서의 encoder는 uni-modal document representation에 적합한 것이 아닐까하는 생각이 듦
- 그리고 encoder-decoder의 initializing을 각기 다른 모델로 하면 (e.g. BERT2GPT) document summarization에 효과적이지 않음
- BERT2GPT, RoBERTa2GPT < RND2GPT (CNN and DailyMail)
- BERT2GPT < RND2GPT (BBC)
- 하지만, Gigaword dataset에서의 경우, BERT2GPT, RoBERTa2GPT > RND2GPT임
- 이 경우에는 document-level summarization이냐 sentence-level-summarization이냐에 따라 성능이 다르므로, task별로 적절한 조합이 다르다고 받아들이는 것이 좋겠다고 사료됨
- 주목할 것은 GPT(only)가 RND2GPT, BERT2GPT, RoBERTa2GPT와 같은 encoder를 붙인 모델들의 성능을 모두 outperform하였다는 것임 (CNN and DailyMail dataset한정)
- Document understanding
- Abstractive summarization
'AI > NLP' 카테고리의 다른 글
| Evaluation Metrics for Language Models (0) | 2024.01.10 |
|---|---|
| GPT decides to stop generation: Semantics of the Unwritten, The Effect of End of Paragraph ... (0) | 2024.01.09 |
| Open Source GPT-3 (GPT-Neo, GPT-J) (0) | 2024.01.08 |
| GPT-2 : Language Models are Unsupervised Multitask Learners (0) | 2022.06.29 |
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (4) | 2022.06.28 |



