본 포스팅은 GPT-2의 논문 리뷰를 다루고 있습니다.
개인적 고찰은 파란색으로 작성하였습니다. 해당 내용에 대한 토론을 환영합니다 :)
Background (Motivation)
- 다양한 NLP task(question and answering, machine translation, summarization)들은 task-specific한 dataset과 그에 맞는 fine-tuning을 요구함
- 이는 ML 전반에서 typical한 model 구축/생성 방식이라고 생각함
- 특정 domain에서, 특정 task를 잘 수행하는 ML model을 만들기 위해서 task에 맞는 domain의 dataset을 구축해야하고,
- 기대하는 task를 잘 수행할 수 있게 학습시키고 (supervision을 통해)
- i.i.d held-out dataset들에 대해서 검증해가면서 이 수행 능력을 고도화해감
- 그러나, 결론적으로 이러한 모델들은 "Narrow expert" 에 불과함
- 최근 하나의 단일 모델을 통해 여러 task를 수행하고자하는 움직임이 커지며, transfer learning, multi-task learning과 같은 learning 방법이 연구되었으며, 보다 General model을 지향하게 됨
- 이러한 흐름에서 각기 다른 task마다 그에 맞는 dataset과 훈련을 시켜야하는 문제가 발생
- 본 논문의 저자는 기존 ML의 관습적 행태에 의문을 갖고, pre-trained model을 통해 zero-shot downstream task를 가능한 general model을 구축하고자 하였음 (motivation)
Method (Approach)
- 목표한 generalist model을 구축하기 위해서, Language modeling이 핵심
- Language modeling은 문장들이 어떠한 token sequence로 구축되어 있는지를 모델링하는 것을 의미함
- (보다 통계학/수식적으로 이야기하자면) 문장은 token들을 발생시키는 분포로 간주할 수 있고, Language modeling은 token들을 통해 문장의 분포(unsupervised distribution)를 estimation하는 것으로 생각할 수 있음
$$ p(x) = \Pi_{i=1}^{ n} p(s_n|s_1, ..., s_{n-1}) $$ - $ p(x) $ : 문장의 unsupervised distribution
- $ x_i $ : 문장
- $ s_i $ : 단어 token
- (보다 통계학/수식적으로 이야기하자면) 문장은 token들을 발생시키는 분포로 간주할 수 있고, Language modeling은 token들을 통해 문장의 분포(unsupervised distribution)를 estimation하는 것으로 생각할 수 있음
- 그러므로, 어떠한 task를 수행함을 learning한다는 것은 $\bf{p(output|input)}$의 conditional distribution을 estimating하는 것이라고 볼 수 있음
- General model은 같은 input에 대해서 다양한 task를 수행가능해야하므로, $\bf{p(output|input)}$을 estimating해야한다. (multi-task나 meta-learning objective)
Training dataset
- 본 논문의 핵심은 unsupervised pre-training을 통해 zero-shot downstreaming task를 학습하는 것
- 그러므로 다양한 domain과 context에서 NLP task를 수행하도록 가능한 크고 다양한 dataset을 구성해야함
- 각 task별로 dataset을 따로 구축하지 않고 최대한 다양한 language data를 구축하기 위해 web crawling dataset을 사용함
- WebText
- Reddit에서 최소 3 karma를 받은 게시물을 crawling (배경지식: Redditdms like/dislike개념인 upvote/downvote가 있는데, 두 개의 count를 각각 +1, -1로 계산하여 합한 것이 karma point ─ e.g. 3 upvote - 1 downvote = 2 karma)
- 40 GB
- 8M docs
- Reddit을 통해 crawling된 Wiki docs들은 모두 제거 ─ 다른 dataset에서도 이용가능하므로 제외했다고 함
Input Representation
- BPE(Byte Pair Encoding) 방식을 채택
- word → character 단위로 분해하여 vocab을 생성
- 이후 반복되는 character pair를 vocab에 추가하는 방식
- 그러나, Byte Pair encoding이라는 이름과는 달리 아래 예시에서와 같이 Unicode sequence에서 적용됨
- Unicode sequence형태로 encoding시 130k개 이상의 vocab이 필요함 (generally, 32k~64k정도)
- Byte단위로 encoding시에는 256개의 size로도 모두를 cover할 수 있음
- 하지만, 이 역시도 단점이 존재하는데, 높은 빈도수에 따라 subword를 구축하는 greedy 방식때문에 dog라는 단어만 구축하길 원하지만, 실제로 문장부호와 함께 data 내에서 여러 번 출현 하였다면 {dog, dog?, dog!} 와 같이 그대로 추가함
- 이에, Byte sequence를 채택하되, character 수준 이상의 merge를 막음
- Vocab size : 50,257
- Context size : 512 → 1024 tokens (maxlen)
- Batch size : 512
● BPE
Word = {low, lowest, newer, wider}
Vocab = {l, o, w, e, s, t, n, i, d, r}
→ Word = {low, lowest, newer, wider}
Vocab = {l, o, w, e, s, t, n, i, d, r, low, er} : 반복된 character pair(low, er)를 추가
* low = lo + w 또는 l + ow
source: https://aclanthology.org/P16-1162.pdf
Model architecture

- 차이점은, Layer Normalization의 위치
- GPT-1 : FFN(feed forward network) 앞 뒤
- GPT-2 : Masked multi-head self-attention 앞 뒤 (input부분으로 이동)
- GPT-2에서는 최대한 방대한 데이터를 통해 많은 domain과 다양한 task를 cover해야하기때문에 embedding 다음의 module인 Masked multi self-attention이 더 중요해짐
- 특히나, zero-shot learning을 지향한다면 더더욱 embedding을 잘 뽑아내야 stable transferring을 할 수 있을 것
- 그리고, $1/\sqrt{N} \cdot weight$ 을 residual layer의 weight initializer로 사용 (N : residual layer의 개수)
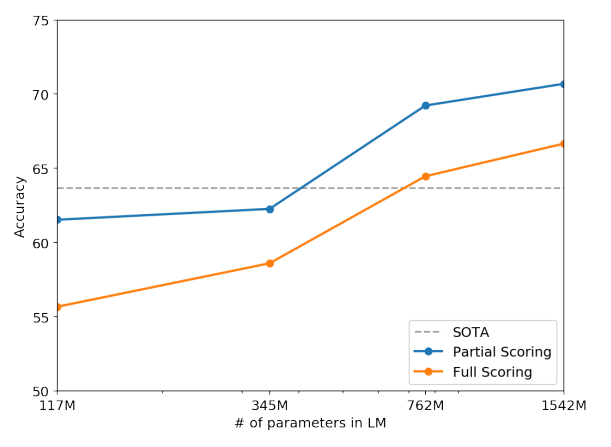
TASK
- Language Modeling
- 해당 모델이 language dataset에 대해 얼마나 modeling을 잘하는지
→ Canonical prediction unit별 (e.g. a character, a byte of word)로 average negative log probability를 측정
→ Sentence 내의 token unit 분포를 얼마나 잘 modeling하였는지 log-likelihood ─ $log P(unit_1 | unit_2, unit_3, ..., unit_n)$ ─를 계산하는 것 - 목적대로, 어떠한 fine-tuning없이 바로 Language Modeling을 수행
- 아래 표) 좌측 column은 # of parameters in LM : 117M, 345M, 762M, 1542M
- PPL. : perplexity(↓, 낮을수록 좋은 것), 간단하게, 특정 시점에서 LM이 정답을 내기 위해 평균적으로 몇개의 보기를 가지고 고민하는가?
$$ PPL(W) = P(w_1, w_2, w_3, ..., w_N)^{-\frac{1}{N}} = \sqrt[N]{\frac{1}{P(w_1, w_2, w_3, ..., w_N)}} = \sqrt[N]{\frac{1}{\Pi_{i=1}^N P(w_i | w_1, w_2, ..., w_{i-1})}} $$ - ACC. : accuracy(↑, 높을수록 좋은 것)
- Pre-processing이나 tokenization이 필요없음
- WebText dataset에 대해서는 <UNK>이 40B-bytes 중 26번정도 밖에 나타나지 않음
- Zero-shot으로 8개 benchmark dataset 중 7개의 SOTA달성
- 특히, small-dataset (WikiText-2, PTB)에 대해서 1~2M개의 token으로 large improvements를 보임
- Long-term dependency를 가지는 LAMBADA나 Children's Book Test에서도 large improvements를 보임 (Long-term dependency인 이유는 많은 문장을 보고 답을 내려야하는 task이기 때문 ─ 자세한 내용은 후술)
- 해당 모델이 language dataset에 대해 얼마나 modeling을 잘하는지

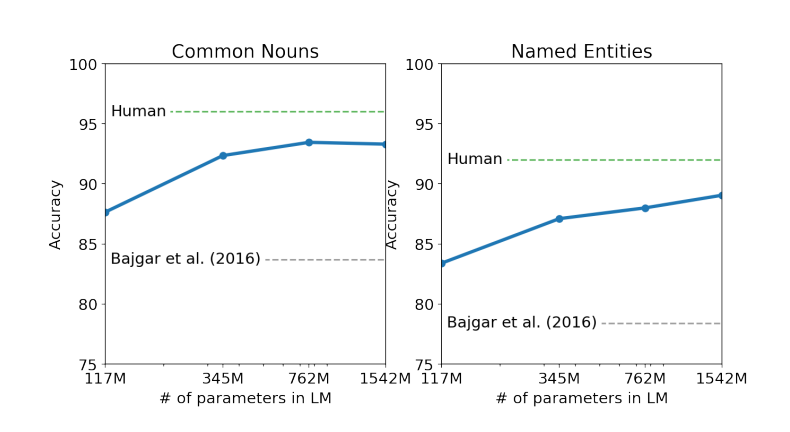
- Children's Book Test
- CBT는 10개의 보기 중 an omitted word에 적합한 보기를 choice하는 task를 수행함 (ref) (Fig 2)
- 각 word category별 (named entity, nouns, verbs, pre-positions) Language Modeling의 성능을 측정
- 모델의 parameter 수에 비례하여 성능이 증가, 가장 큰 모델의 경우 Human의 성능에 근접 (Fig 3)

- LAMBADA
- Sentence의 마지막 word를 predict하는 task를 수행
- Human의 기준으로 약 50개의 token으로 구성된 정보를 바탕으로 추론해야하는 수준의 task임
- 앞서 언급한 표에서 LAMBADA column의 결과
- PPL.(perplexity)를 99.8 → 8.6으로 개선
- ACC.를 19% → 52.66%로 개선
- Winograd Schema Challenge
- ambiguities in text를 푸는 능력을 측정
- 예) The city councilmen refused the demonstrators a permit because they [ feared / advocated ] violence.
- 핵심은 they가 councilmen을 가르키는 것인지, demonstrators를 가르키는 것인지 문맥으로 유추해야하는 것
- human에게는 context를 읽어내어 쉽게 they가 demonstrators라는 것을 유추해내기 쉬우나, machine에게는 굉장히 challenging한 task임
- ambiguities in text를 푸는 능력을 측정
- Reading Comprehension
- Conversation Question Answering dataset (CoQA)을 이용
- 7개의 domain에서 natural language dialogues와 Q, A를 포함하고 있는 dataset
- Reading comprehension와 QA ability를 동시에 평가할 수 있음
- 4개 중 3개의 baseline model을 outperform
- baseline model에서는 127,000+의 maunally collected QA pair를 추가로 훈련하였음에도 GPT-2는 이 훈련과정없이 outperform하였음
- 그러나, SOTA인 BERT의 성능 (human performance인 F1 score 89에 인접한 score)에 미치지 못하였지만, supervised fine-tuning없이 F1 score 55를 달성함 → QA의 heuristics를 배우기도 하였음 (Who를 묻는 질문에 document내의 이름을 답으로 내놓는 등)
- Conversation Question Answering dataset (CoQA)을 이용
- Translation
- WMT-14 Eng-Fre dataset을 활용하여 영어↔불어 번역 task를 수행
- 다른 task에 비해 괄목할만한 성과를 달성하지 못하였음
- Fre → Eng의 경우, SOTA 수준은 아니지만 기존 번역 모델보다는 좋은 수준을 보임
- Eng → Fre의 경우, word-by-word로 번역하는 수준보다도 좋지 못한 성능을 보임
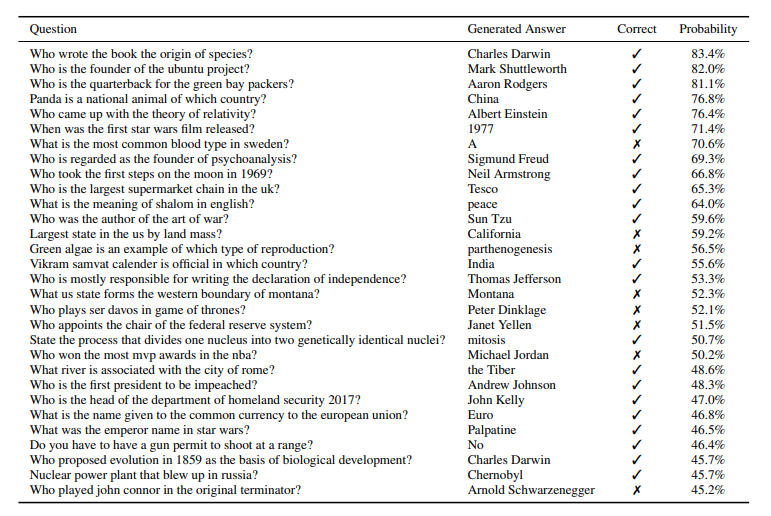
- Question Answering
- EMR (Exact Match Ratio, 완천 일치 metric)으로 평가 시, 4.1%의 정확도를 달성 (기존 모델 대비 5.3배 성능)
- 아래 표는 QA task에 대해서, 각 질문에 대해 GPT-2가 내놓은 answer들을, probability(score)가 높은 순서대로 Top 30을 도출한 내용
- Most confident 1% 질문에 대해서는 평균 63%의 accuracy를 달성