본 포스팅은 Guiding Pseudo-labels with Uncertainty Estimation for Source-free Unsupervised Domain Adaptation논문의 리뷰를 다루고 있습니다.
개인적 고찰은 파란색으로 작성하였습니다. 해당 내용에 대한 토론을 환영합니다 :)
Summary
- SF-UDA (source-free unsupervised domain adaptation)에서 반드시 introduceehlsms pseudo-label
- 이에 따라 learning objective가 noisy pseudo label⎯잘못 만들어진 pseudo label⎯에 영향받지 않게 uncertainty기반으로 loss를 re-weighting하는 방법
Terminology
- Test-time adaptation (TTA) : source domain에서 pretrain된 모델을 target domain에 source-free한 상태에서 adaptation하는 테크닉을 말함 (=source-free DA)
- 말 그대로 Test stage에 adaptation하는 것을 말하는데, source-free한 상황에서 pre-trained source model을 target domain에 adaptation시키는 것을 test-time이라고 간주하는 듯 함
- 일반적인 DA랑 차이점을 살펴보면 아래와 같음
* Target domain이 지속해서 바뀌는 경우(자율주행과 같이 location, weather, time이 바뀌는 상황)가 있으므로 이와 대조적인 개념으로 고정된 target domain이라는 개념의 stationary라는 용어를 씀Data Learning Source Target Source Target Standard DA O stationary
(fixed target domain)O X Test-time adaptation X stationary
(fixed target domainX
(pre-trained)O
Motivation
- Source-Free Unsupervised Domain Adaptation문제를 해결하기 위해 다양한 Topic들이 연구되었음
- generative models, class prototypes, entropy-minimisation, self-training and auxilary self-supervised training
- 하지만, self-training 방법은 대체로 pseudo-label noise에 민감함
- 참고로, 레퍼런스 논문인 SHOT은 entropy-minimisation과 self-training을 위한 pseudo labeling방법임
- Pseudo-label을 이용한 SF-UDA에서 일반적인 문제상황은 pseudo label에 noise가 발생하는 것임
- 이는 Adaptation에서 overfit을 야기하고 이는 domain shift를 해결하지 못하는 것이 됨
- 그래서, pseudo-label을 정제(refine)하는 과정이 필요함
- 문제 setting : Closed set SFDA (즉, target domain과 source domain의 class domain이 같음)
Previous Works
1. MoCo
MoCo: Momentum Contrast for Unsupervised Visual Representation Learning (CVPR 2020)
본 포스팅은 Momentum Contrast for Unsupervised Visual Representation Learning논문의 리뷰를 다루고 있습니다. 해당 논문의 concept위주로 핵심만 다루고자 합니다. Summary MoCo는 Unsupervised visual representation방법임 (s
sumniya.tistory.com
- Self-supervised learning을 위한 Momentum Encoder를 제안
- InfoNCE loss
- Temporal Queue (Quert, Key)방식을 제안
2. AdaContrast
AdaContrast: Contrasitive Test-Time Adaptation (CVPR 2022)
본 포스팅은 Contrasitive Test-Time Adaptation논문의 리뷰를 다루고 있습니다. 해당 논문의 concept위주로 핵심만 다루고자 합니다. Summary Test-time adaptation = source-free adaptation self-supervised contrastive learning을
sumniya.tistory.com
- Target image transform을 통한 data augmentation (week / strong)
- Diversification loss
- Refined pseudo label을 통한 self-supervised 전략을 제안함
Method
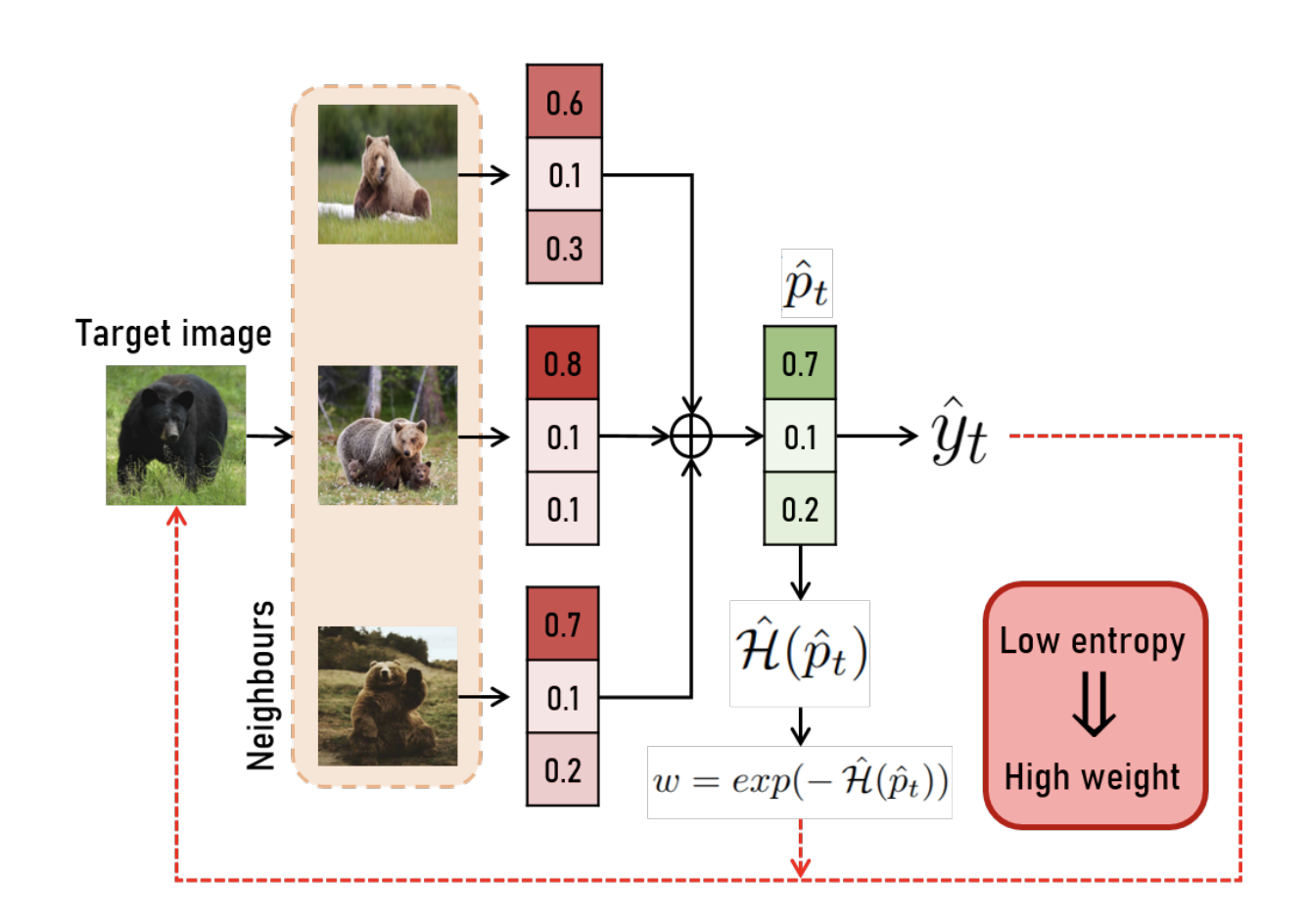
1. Overall framework

(a) Obtain the refined pseudo-label($\hat{y}$)
- Classifier를 통과한 softmax확률의 argmax값으로 주황색 pseudo-labeling
- Neighbor sample들의 pseudo label들을 고려하여 초록색 pseudo-label로 refine
(b) Calculate re-weight, $w$
- Neighbor sample들의 확률값들로 entropy(uncertainty)를 계산
- Entropy값을 loss에서 weight값으로 사용
(c) Negative pair Exclusion for contrastive learning
- 과거 epoch마다 labeling된 pseudo label을 temporal queue에 저장
- 이 history를 참조하여 queue에서 negative sample을 rejection한 뒤, contrastive learning에 사용
2. Main Contribution
- Re-weight(Uncertainty, entropy) 도입을 통한 pseudo label에서 발생할 수 있는 noise smoothing효과
- Noise PL(pseudo-label)을 구분하고 처리 (with temporal queu) — negative sample exclusion전략 활용
- SF-UDA에서 PL을 refine하는 approach의 타당성을 실험적으로 입증
3. Method detail
(1) Pseudo-label Refinement via nearest neighbors knowledge aggregation
핵심 가정은, similar sample들은 같은 PL을 가지고 있다는 것임.
features from semantically similar image should lie close in the feature space.
- target image $x_t$에 대해서 weak augmentation $t_{wa}$를 week augmentation 분포 $T_wa$로부터 뽑아 weakly augmented image $t_{wa}(x_t)$를 생성
- feature extractor를 통과한 feature vector $z$를 생성, $z = f_t(t_{wa}(x_t))$ ($f_t$: feature extractor)
- 이 $z$를 이용하여 target feature space에서 $x_t$의 neighbor들을 euclidean 혹은 cosine distance 기반으로 선택
- Neighbor들의 softmax probability output의 soft-voting으로 $x_t$의 pseudo label을 refine
(2) Loss Reweighting with Uncertainty
- Refine을 시켰다고 해도, noisy PL이 존재하지 않는 것은 아니지만, 기존 approach들은 PL의 noisy함을 판단하는 기준이 없었음
- 그러므로, (noisy PL을 포함한) 모든 PL이 self-training을 하는데 동일한 weight을 사용하여 학습됨
- 본 논문에서는 noisy PL을 판단하고 이 sample들에 penalize하는 것이 핵심 아이디어임
- Re-weight = neighbor sample들의 entropy값
- PL을 refine시킬 때 neighbor들의 prediction을 기반으로 하였기 때문에, noisy PL을 찾는 척도도 neighbor들의 PL로 잡음
- 모든 neighbor들이 같은 class probability로 예측하면 entropy가 낮게 측정되고, 이는 높은 weight을 가지도록 설정함
- 구체적으로는, neighbor들의 predicted probability를 계산하고 class별 average를 계산 ($\hat{p}_t$)
- 이 probability의 entropy를 측정한 후($\hat{\mathcal{H}}(\hat{p}_t))$, -를 붙여 exponential한 것을 weight($w$)으로 사용함
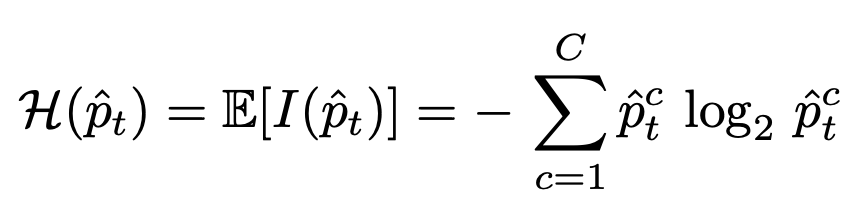
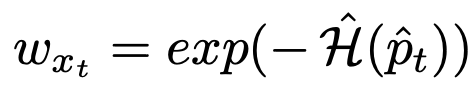
(3) Temporal Queue for Negative Pairs Exclusion
- 현재 epoch의 PL뿐만 아니라 과거 이력을 확인함으로써, 현재 epoch의 noisy PL에 강건하게 대응함
- Positive Pair : 같은 PL class를 가진 sample pair
- Negative Pair : 다른 PL class를 가진 sample pair
- Contrastive Test-Time Adaptation 논문에서 current PL 결과만으로 negative pair를 masked out하였음
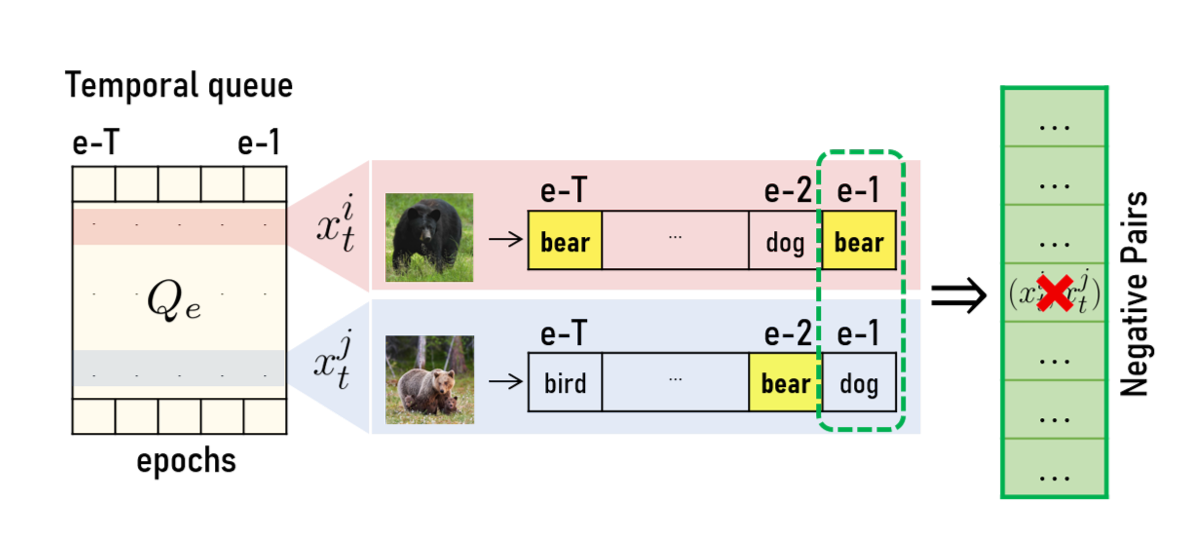
- 하지만, 그럴 경우, 같은 class임에도 latest prediction결과에 따라서 negative pair가 될 수 있음
- 그래서, 본 논문에서는 epoch마다 과거 PL을 Temporal Queue에 저장해두고(=T epoch만큼) 이 Queue 내에서 적어도 한번은 같은 PL을 공유했으므로 negative pair에 들어오지 않도록 제외함
(4) Joint Training with Self-Learning
- Re-weighting과 Exclusion 전략으로 PL의 noise를 줄인 refined PL을 통해 다음의 3가지 loss 합으로 loss를 design함
- Weighted negative learning loss (for classification loss) ―$L_t^{cls}$ ($p^c_{sa}$ : refined pseudo label)
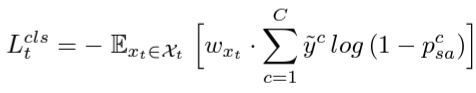
- InfoNCE loss (for contrasitive loss)
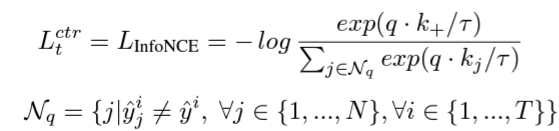
- Diversification loss (for posterior collapse 완화) ―$L_t^{div}$




