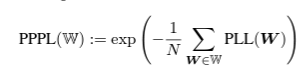언어모델(Language Model)의 성능을 측정하는 방법은 여러가지가 있습니다. NLP에는 Summarization, Translation, Story generation 등 다양한 task가 존재하는데, 그 목적에 따라 관심 갖는 평가가 다를 수 있습니다. 예를 들면, 번역의 경우 source 언어로부터 다양하게 target 언어를 만들어 낼 수 있으므로 모델이 만들어내는 결과에 초점을 맞추는 것이 중요합니다. 반면, 요약의 경우에는 마찬가지로 다양한 문장으로 요약될 수 있지만 반드시 포함되어야 하는 키워드를 얼마나 재현하는 지가 중요할 것입니다. 이렇듯 다양한 task에 부합하는 평가 지표를 사용하는데, 대표적으로 Perplexity (PPL), BLEU, ROUGE가 있습니다.
Perplexity (PPL)
직역하자면 당혹감, 헷갈리는 정도인데 generation task에서는 모델이 이전 출현 word대비 다음 word를 예측할 조건을 계산하게 되는데, 이때, 모델이 일련의 sequence를 보며 이전에 보지 못한 word(즉, 다음 word)를 얼마나 잘 예측하는지를 평가하자는 것이 perplexity의 개념입니다.
직관적인 해석으로는 모델이 다음 word를 예측할 때, 몇 개의 보기로 얼마나 확신해서 예측하느냐?를 말합니다.
Countclip은 generated sentence의 단어가 refrence sentence에서 등장한 최대 단어 개수와 generated sentence 자신에서 등장한 빈도 중 최솟값을 택하게 하는 알고리즘입니다. 이를 이용하면 중복이 아무리 많더라도 reference sentence에서 등장한 최대 단어 개수를 고려할 수 있습니다. 그리하여, 수정된 Unigram precision은 아래와 같습니다.
💡Modified Unigram Precision $ = Count_{clip} $ / Gen의 총 단어 수 $ = \min(count, max\_ref\_count) $ / Gen의 총 단어 수
Example 2에서 Generated2를 추가하고 Uni-gram에서 Bi-gram으로 확장해봅시다.
Generated1는 $ \frac{0}{6} = 0 $
Generated2는 아래와 같이 $ \frac{4}{6} $으로 구할 수 있습니다.
bi-gram
(the, cat)
(cat, the)
(cat, on)
(on, the)
(the, mat)
합
Count
2
1
1
1
1
6
Countclip
1
0
1
1
1
4
❔ 보완점
순서에 맞춰서 단어를 잘 generate하는 것만으로도 충분할까요?
순서에 맞춰서 단어를 잘 generate하면서 최대한 길게길게 문장을 생성하면 Ref를 모두 cover하는 문장을 생성해 낼 수 있을 것입니다.
또한, 반대로 확실하게 맞출 수 있는 단어만 짧게 generate해도 지금까지의 방법으로 좋은 score를 받을 수 있는 문장입니다.
하지만, 이러한 문장은 좋은 quality의 생성문장이 아닙니다.
(4) Brevity Penalty - 문장 길이
Generation 길이에 n-gram precision이 크게 영향을 받아 이를 보완해봅시다.
✅ Example 4-1 (짧은 길이)
Generated1 : It is
Reference1 : It is a guide to action that ensures that the military will forever heed Party commands.
Reference2 : It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference3 : It is the practical guide for the army always to heed the directions of the party.
Unigram, Bi-gram이 각각 $\frac{2}{2}$, $\frac{1}{1}$로 모두 1이라는 이상적인 score가 도출 되었습니다.
이와 같이, 모델의 generation sentence가 짧을 때 높은 score를 달성하는 것을 방지하기 위해, 짧은 길이에 대한 penalty를 부여합니다.
이를 Brevity Penalty(BP)라고 부릅니다.
💡Brevity Penalty (BP) - c : generation sentence의 길이 - r : generation sentence와 가장 길이 차이가 작은 reference sentence의 길이
💡BLEU w/ BP $BLEU = BP \times \exp (\sum^N_{n=1} w_n \log p_n )$
✅ Example 4-2 (긴 길이)
Generated1 : I always invariably perpetually do.
Generated2 : I always do.
Reference1 : I always do.
Reference2 : I invariably do.
Reference3 : I perpetually do.
길이가 긴 case에 대해서도 살펴보겠습니다.
Generated1은 Reference1, Reference2, Reference3의 단어를 모두 포함하면서 긴 문장을 완성하였지만, Generated2보다 좋은 문장은 아닙니다. 그러므로 이렇게 불필요한 길이의 generation을 방지하는 대책이 필요한데, n-gram으로 확장하면서 어느 정도 긴 문장에 대한 penalty를 받고 있습니다. 이 사실을 이용하여 n-gram을 n=1, 2, 3, 4일 때의 score를 구해 평균을 내는 것이 그러한 효과를 얻을 수 있겠습니다.
ROUGE
들어가기에 앞서, 다시 한번 remind하자면 ROUGE score는 Recall-Oriented Understudy for Gisting Evaluation의 앞 글자를 딴 지표입니다. 그 이름에서 알 수 있다시피 recall을 base로 측정하는 지표인데, ROUGE N-gram, ROUGE-S, ROUGE-SU, ROUGE-L, ROUGE-W 등 다양한 variation이 있으며 일반적으로 Text Summarization 성능 평가에 이용됩니다. Summarization은 human이 수행하더라도 다양한 스타일로 요약이 될 수 있으므로, 보통 핵심 키워드의 포함 여부가 관건입니다. 즉, 핵심 키워드(=정답) 중 얼마나 모델이 재현했는가로 판단하는 것이죠(=Recall)
ROUGE-N
: N-gram co-Occurrence Statistics
특징
정답 문장의 단어가 생성 문장에 포함되는 정도를 default로 사용
각각의 n-gram생성
Multiple reference(복수 정답)
한계점
연속된 단어만 정답이 됨
단순히 단어의 출현만 볼 경우, n-gram내에 등장하지 않을 경우 산정이 안 될 수 있음
ROUGE-S
: ROGUE + Skip-gram
특징
Basic n-gram대신 skip n-gram을 사용하여 위에서 언급한 한계점을 극복 가능함
F1-score이용
생성 문장의 단어가 정답 문장에 포함되는 정도 (precision) + 정답 문장의 단어가 생성 문장에 포함되는 정도 (recall)
n-gram대신 정답과 생성 문장 사이의 최장 공통 부분 수열(LCS: Longest Common Subsequence)를 이용하여 유사도 계산
최장 공동 부분 수열은 부분 수열이기때문에 문자 사이를 건너뛰어 공통되면서 가장 긴, 부분 문자열을 찾는 알고리즘
F1-score이용 = Precision + Recall (ROGUE-S와 동일한 특징)
예시1
Generation : ABCDEF
Reference : ACBDXF
LCS결과 : ABDF
예시2
Generation :ABCDEF
Reference : GBCDEA
LCS결과 : BCDE
추가 응용 방법
Sentence-level LCS
Summary-level LCS (Union)
Normalized Pairwise LCS
ROUGE-W
: ROUGE + Weighted Longest commom subsequence
특징
LCS를 이용하면 순서에 관한 유사도만 계산하게 되는데 이를 weight을 주어 개선
F1-score이용 = Precision + Recall (ROGUE-S와 동일한 특징)
예시
Generation :ABCDEFG
Reference1 : ABCDHIK
Reference2 : AHBKCID
Ref1, Ref2의 LCS결과는 같음
하지만 Ref1이 연속되어 붙어있는 단어 시퀀스이므로 이에 더 가중치를 부여함
Appendix
아래는 Project시, 데이터 상 BLEU score의 4가지 조건들을 모두 사용할 필요가 없어 custom한 BLEU score를 만들었는데,
이를 구현한 코드입니다.
단적으로, 저는 단어의 순서를 고려할 필요가 없어 n-gram이 아닌 Unigram만을 사용하였습니다.
def sentence_modified_precision(candidate_list, reference):
return [modified_precision(candidate, [referece]) for candicate in candidate_list]
def modified_precision(candidate, reference_list, n=1):
clip_cnt = count_clip(candidate, reference_list, n)
total_clip_cnt = sum(clip_cnt.values()) # 분자
cnt = simple_count(candidate, n)
total_cnt = sum(cnt.values()) # 분모
# 분모가 0이 되는 것을 방지
if total_cnt == 0:
total_cnt = 1
# 분자 : count_clip의 합
# 분모 : 단순 count의 합
# --> 보정된 정밀도
return (total_clip_cnt / total_cnt)
def count_clip(candidate, reference_list, n=1):
# Ca 문장에서 n-gram count
ca_cnt = simple_count(candidate, n)
max_ref_cnt_dict = dict()
for ref in reference_list:
# Ref 문장에서 n-gram count
ref_cnt = simple_count(ref, n)
# 각 Ref 문장에 대해서 비교하여 n-gram의 최대 등장 횟수를 계산
for n_gram in ref_cnt:
if n_gram in max_ref_cnt_dict:
max_ref_cnt_dict[n_gram] = max(ref_cnt[n_gram], max_ref_cnt_dict[n_gram])
else:
max_ref_cnt_dict[n_gram] = ref_cnt[n_gram]
return {
# count_clip = min(count, max_ref_count)
n_gram: min(ca_cnt:get(n_gram, 0), max_ref_cnt_dict.get(n_gram, 0))
for n_gram in ca_cnt
}
from collections import Counter
from nltk import ngrams
def simple_count(tokens, n):
return Counter(ngrams(tokens, n))