Transformer-XL : Attentive Language Models Beyond a Fixed-Length Context
본 포스팅은 Transformer-XL : Attentive Language Models Beyond a Fixed-Length Context 논문의 리뷰를 다루고 있습니다.
개인적 고찰은 파란색으로 작성하였습니다. 해당 내용에 대한 토론을 환영합니다 :)
Introduction
Language modeling은 long-term dependency를 modeling하는 전형적인 문제 중 하나입니다. Sequential data를 neural network로 모델링하기 위해서는 이러한 long-term dependecy를 모델링하는 것이 관건이겠습니다. 기존 Language modeling의 standard solution은 RNN, 그 중에서도 LSTM으로 많이 해결하였는데요, RNN은 vanishing/exploding gradients 문제로 optimize하기 어려운 문제가 있었고, 이에 LSTM과 gradient clipping technique이 도입되었지만, 충분히 해결하지 못하였습니다.
실험적으로는, LSTM language model이 200개의 context word를 사용한다고 알려져있습니다. LSTM이 보다 긴 sequence를, 제대로 학습하기 위해서 Attention machanism으로 멀리 떨어진 단어들을 직접적으로 연결하여 optimization과 long-term dependency 해결을 시도하였습니다.
이러한 와중에, Transformer networks이 개발되며 character-level language modeling으로 LSTM을 큰 격차로 outperform하였습니다. 하지만, 이러한 Transformer networks도 문제점/한계점이 존재하였습니다. 가장 두드러지는 문제는 고정된 길이의 segment단위로 학습을 해야한다는 것입니다. 우리가 sequence data, 특히, 언어 모델을 경험적으로 이해하기로는 고정된 길이로만 모든 문장이 이루어지지 않습니다. 또한 이렇게 고정된 길이를 input으로 받다보니 긴 문장을 고정된 길이로 truncate하게 되는데, 이렇게 나누어진 segment단위들 사이에도 정보가 있을 수 있으나, 이를 전혀 이용하지 못하게 됩니다. (fixed input length로 인해, context가 나누어지는 현상이 발생될 수도 있습니다.) 즉, 고정된 길이 내에서의 문맥만 파악할 수 있고, 그 이상의 정보는 얻기 힘들며 이러한 segment들을 나누는 것은 어떠한 의미론적이거나, 문장 보존을 고려하는 방식이 아니라 단순히 고정된 길이로 뚝뚝 자르는 것에 지나지 않습니다. 그리고 이렇게 되면, sequence의 초반부를 학습하는 데에 필요한 문맥 정보가 매우 부족하게됩니다. 본 논문에서는 이러한 Transformer의 문제/한계에 주목하였고, 이를 context fragmentation라고 명명하였습니다.
정리하자면, 본 논문에서는 Transformer의 "고정된 길이"로 발생하는 다음의 문제를 해결하고자 하였습니다.
- 고정된 길이 이상의 context파악이 힘들다
- 단순히 고정된 길이를 잘라 input으로 사용하였기에, segment의 초반부를 예측하기에는 정보량이 부족하다(context fragmentation)
이에, Transformer-XL (extra long)을 제안하여 context fragmentation을 해결하고자하는 것이 본 논문에서 말하고자 하는 바입니다.
Solution은 1) Recurrence의 개념을 self-attention에 도입 2) Relative positional encoding, 두 가지 입니다.
Recurrence
먼저, recurrence의 개념을 self-attention에 도입하였습니다. 구체적으로는, 매 segment마다 hidden state를 아무런 사전 지식 없이 계산하는 것 대신, 이전 segment에서의 hidden state를 재사용하는 것으로 정보량을 늘렸습니다. 이러한 재사용될 hidden state는 현재 segment를 학습할 시 memory 형태로 제공되며, 이는 segment들 사이의 recurrent connection을 만들어 부족한 정보량을 충당할 수 있습니다. 이를 통해서 아주 긴 long term dependency를 모델링할 수 있게 하였고 자연스럽게 context fragmentation을 해결하였습니다.
Relative positional encoding
또한, relative positional encoding으로 기존의 absolute positional encoding을 대체하였습니다. 이는 temporal confusion을 해결하기 위해서인데, 만약 absolute positional encoding을 그대로 사용할 시, 이전 segment의 위치와 현재 segment의 위치를 구분하지 못하게 됩니다. temporal confusion이 말하는 것은, absolute positional encoding을 사용하면 이전 segment의 n번째 위치 단어와 현재 segment의 n번째 위치 단어를 구분하지 못하는 문제를 말하는 것을 말합니다. Transformer-XL은 5개의 dataset(word-level과 character-level language modeling을 모두 포함한)에서 모두 좋은 결과를 나타냈습니다. 또한, 100M개의 token들을 학습하고 몇 천개의 token으로 이루어진 article을 generate하는데에도 능숙하다고 합니다.
Model
기본 Trasformers(Vanilla Transformers)로 Language modeling할 경우에 마주하는 문제는, 한정된 길이로 long context를 encoding해야한다는 것에 있습니다. 이를 위해서 long context를 여러 개의 segment로 나누어 학습하는 방법이 있으나, 이렇게하면 각각의 segment 내의 context는 학습할 수 있지만, segment간의 contextual information은 고려하지 못하게 됩니다. (Context fragmentation)
먼저, 논문에서 정의하는 Language modeling은 auto-regressively factorized joint probability를 estimate하는 것으로 정의하였습니다. 이 말을 이해하기 위해서 차근차근 살펴보겠습니다. 자연어 데이터는 일종의 token의 나열로 간주할 수 있고, 이 token들은 어떠한 말뭉치에서 나온다고 생각할 수 있습니다. 즉, 우리가 정치기사를 쓴다고 가정할 때 말뭉치에 포함될 수 있는 token들은 정당, 중립, 국회 등등이 될 수 있겠죠. 이를 수식으로 표현하자면 a corpus of tokens, \( \textbf{x} = (x_1, ..., x_T) \)로 나타낼 수 있습니다. 그리고 이러한 token들로 문장을 만든다고 할때, token으로 문장이 나오는 분포를 가정할 수 있고 그것을 다음과 같이 표현할 수 있습니다.
$$ sentence = P(\textbf{x}) = P(x_1, ..., x_T) = \prod_{t}{P(x_t|\textbf{x}_{<t})}$$
이는, \( P(x_1, ..., x_T) = P(x_1)P(x_2|x_1) \cdots P(x_t|x_1, x_2, ..., x_{t-1}) \)을 단순화시킨 식입니다. Auto-regressive model은 자기 자신을 입력으로 자기 자신을 예측하는 모델을 말합니다. 위 수식을 기반으로 언어 모델링을 생각한다면, 문장을 이루는 token들을 input으로 문장 생성 분포를 예측하므로, auto-regressive함을 알 수 있습니다.
Vanilla Transformer Language Models
Transformer가 위 수식에서 product term 내에 있는 conditional probability를 다음과 같이 모델링합니다.
- t시점 이전의 context( \( \textbf{x}_{<t} \) )를 고정된 길이로 encoding하여 hidden state를 만듦
- 이 hidden state와 word embedding을 곱하여 logit을 얻음
- logit에 Softmax function을 적용하여 다음 token에 대한 Categorical probability distribution으로 만듦

Train과정은 Figure 1-(a)(검은 실선 기준 왼쪽 그림)을 보시면 전체 corpus를 고정된 길이(=4)만큼의 segment로 나누고 각각의 segment를 독립적으로 학습하는 것을 알 수 있습니다. 이렇게하면 이전 segment를 전혀 고려할 수 없이, 주어진 segment만을 학습하게 됩니다. 또한 evaluation과정에서는 고정된 길이의 input을 통해 마지막 position의 token만을 예측하고 오른쪽으로 하나씩 이동하여 다음을 예측합니다. 하지만 이는 굉장히 time-consuming한 방법입니다.
Transformer-XL
관건은 "한정된 resource를 가지고 고정된 길이로 어떻게 긴 context를 모델링하느냐"입니다. Figure 1과 비교하여 아래 그림을 통해 Transformer-XL이 하고자하는 바를 살펴보겠습니다. 위 그림과는 대조적으로 반영되는 context길이가 긴 것을 한눈에 알 수 있습니다.

Transformer-XL은 1) 이전 state의 저장 및 재사용 그리고 2) relative positional encodings로 보다 긴 context를 모델링하도록 설계되었습니다.
1) State Reuse : 이전 segment에 대한 hidden state가 계산된 후 저장(cached)되어 다음 segment의 hidden state를 계산할때 이용됩니다. Figure 2-(a)의 gray box가 이전 segment에 대한 hidden state입니다. 그림에서 New segment를 학습할 때 이 hidden state를 이용합니다. 이렇게되면, 이전 segment와의 context 연속성이 생기고 자연스럽게 vanilla transformer보다 긴 context를 모델링할 수 있습니다. 길이 \( L \)의 연속된 sequence \( \textbf{s}_{\tau} = [x_{\tau,1}, \cdots, x_{\tau,L}] \)와 \( \textbf{s}_{\tau+1} = [x_{\tau+1,1}, \cdots, x_{\tau+1,L}] \)에 대해, \( \textbf{s}_{\tau} \)의 n번째 hidden state를 \( \textbf{h}_{\tau}^{n} \)라고 하면, \( \textbf{s}_{\tau+1} \)의 n번째 hidden state, \( \textbf{h}_{\tau+1}^{n} \)는 다음과 같이 나타낼 수 있습니다.
$$ \textbf{h}_{\tau+1}^{n} = \text{Transformer-Layer}(\textbf{q}_{\tau+1}^{n},\textbf{k}_{\tau+1}^{n},\textbf{v}_{\tau+1}^{n}) $$ Transformer와 마찬가지로, attention을 이루는 query, key, value들이 Transformer layer의 component로 들어갑니다. 각 요소는 아래와 같이 씁니다.
$$ \textbf{q}_{\tau+1}^{n},\textbf{k}_{\tau+1}^{n},\textbf{v}_{\tau+1}^{n} = \textbf{h}_{\tau+1}^{n-1}W_{q}^{\top}, \tilde{\textbf{h}}_{\tau+1}^{n-1}W_{k}^{\top}, \tilde{\textbf{h}}_{\tau+1}^{n-1}W_{v}^{\top}$$
$$ \tilde{\textbf{h}}_{\tau+1}^{n-1} =[\text{SG}(\textbf{h}_{\tau}^{n-1}) \circ \textbf{h}_{\tau+1}^{n-1}]$$
key와 value를 만드는데 query와는 다른 component를 사용합니다. 여기서 사용하는 \( \tilde{\textbf{h}}_{\tau+1}^{n-1} \) 는 기존 hidden state와는 다르게 extended context를 모델링한 hidden state라고 보시면 되겠습니다. \( \tilde{\textbf{h}}_{\tau+1}^{n-1} \) 을 만드는 수식을 보면 SG는 stop-gradient, \( \circ \) 연산은 concatenation을 의미합니다. 여기서 \( \tilde{\textbf{h}}_{\tau}^{n-1} \)은 \( \tau \) segment의 n-1번째 hidden state를 의미합니다. 수식을 통해서 보면, 이전 hidden state를 stop gradient로 fixed시키고 다음 \( \tau+1 \) segment의 hidden state와 concate하여 확장된 hidden state를 만드는 것을 알 수 있습니다. 이는 위 그림에서 초록색 실선으로도 잘 나타내고 있습니다.
이렇게 segment-level로, 이전 segment의 hidden states가 다음 segment의 hidden states에 영향을 주는 recurrence를 발생시키게되면, 수식적으로도 알 수 있 듯 하나의 layer shift가 발생됩니다―$\textbf{h}_{\tau+1}^{n}$, $\textbf{h}_{\tau}^{n-1}$. 전통적인 RNN계열의 LM들은 이러한 layer shift없이, 같은 layer 안에서만 recurrence가 발생시키는 구조이죠. 그래서 결과적으로는 고려가능한 length dependency가 layer의 수에 linear하게 증가하게 됩니다―$O(N \times L)$. Figure 2-(b)의 shaded area가 이를 보여주고 있습니다. 그리고, 이렇게 fixed and cached 후 reuse하는 방식은 computation 속도를 빠르게 해주는 이점도 있습니다. 또한, GPU memory가 받쳐주는 한 이전 segment만 고려하는 것이 아닌 더 이전의 segment를 고려하여 더 긴 context를 고려하게 할 수도 있습니다.
2) Relative Positional Encodings : 앞서 언급한 state reuse를 사용할 때, positional information을 고려하는 것이 필요합니다. $\textbf{U}$를 positional encoding이라고 한다면, standard Transformer에서는 sequence order의 정보를 총 길이 $L_{max}$에서 element마다 word embedding과 맵핑되는 absolute position형태로 주어집니다.
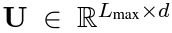
만약, state reuse에 그대로 적용한다면, 아래와 같이 쓸 수 있는데, 여기서 문제가 생깁니다.
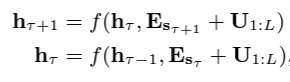
($\textbf{E}_{s_{\tau}} \in \mathbb{R}^{L \times d}$는 word embedding of sequence $\textbf{s}_{\tau}$, $f$는 transformation function)
보시다시피, $\textbf{E}_{s_{\tau+1}}$와 $\textbf{E}_{s_{\tau}}$가 모두 같은 positional encoding $\textbf{U}_{1:L}$을 갖게 됩니다. 따라서, $x_{\tau, j}$와 $x_{\tau+1, j}$의 positional difference를 고려하지 못하게 되죠.
이를 해결하기 위해 도입된 아이디어가 바로 relative positional encoding입니다. 핵심은 절대적인 위치 정보를 encoding하는 것이 아닌, 두 position의 차이를 encoding하는 방식입니다.
먼저, standard Transformer에서 $q_i$와 $k_j$사이의 attention score는 다음과 같이 decompose할 수 있습니다.
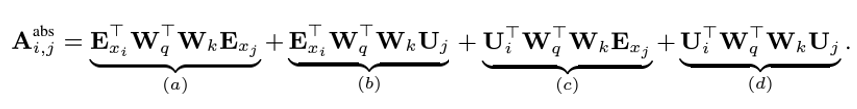
여기서 4가지의 parameter들을 도입하여 relative positional encoding을 바꾸면 아래와 같습니다.
$$ \begin{align*} (a), (c) &= \textbf{E}_{x_i}^{\top} \textbf{W}_{q}^{\top} \textbf{W}_{k} \textbf{E}_{j}+\textbf{U}_{i}^{\top} \textbf{W}_{q}^{\top} \textbf{W}_{k} \textbf{E}_{x_j} \\ &= (\textbf{E}_{x_i}^{\top} \textbf{W}_{q}^{\top} + \textcolor{red}{\textbf{U}_{i}^{\top} \textbf{W}_{q}^{\top}}) \textcolor{green}{\textbf{W}_{k}} \textbf{E}_{x_j} \\ &= (\textbf{E}_{x_i}^{\top} \textbf{W}_{q}^{\top} + \textcolor{red}{u^{\top} } ) \textcolor{green}{\textbf{W}_{k, E}} \textbf{E}_{x_j} \end{align*} $$
$$ \begin{align*} (b), (d) &= \textbf{E}_{x_i}^{\top} \textbf{W}_{q}^{\top} \textbf{W}_{k} \textbf{U}_{j}+\textbf{U}_{i}^{\top} \textbf{W}_{q}^{\top} \textbf{W}_{k} \textbf{U}_{j} \\ &= (\textbf{E}_{x_i}^{\top} \textbf{W}_{q}^{\top} + \textcolor{red}{\textbf{U}_{i}^{\top} \textbf{W}_{q}^{\top}}) \textcolor{purple}{\textbf{W}_{k, R}} \textcolor{cyan}{\textbf{U}_{j}} \\ &=(\textbf{E}_{x_i}^{\top} \textbf{W}_{q}^{\top} + \textcolor{red}{v^{\top} } ) \textcolor{purple}{\textbf{W}_{k, R}} \textcolor{cyan}{\textbf{R}_{i-j}^{\top}} \end{align*} $$
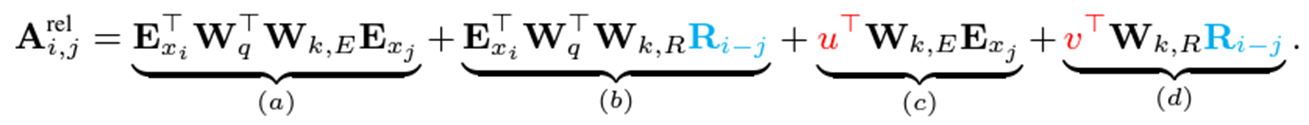
변경된 내용을 정리하자면,
- (b), (d)에서 $\textbf{U}_j \rightarrow \textbf{R}_{i-j}.$ absolute positional embedding, $\textbf{U}_j$를 relative positional embedding, $\textbf{R}_{i-j}$로 바꾸었습니다.
- (c)에서 $\textbf{U}_i^{\top} \textbf{W}_{q}^{\top} \rightarrow u^{\top}.$ 여기서는 query vector에 해당하는 $ \textbf{U}_i^{\top} \textbf{W}_{q}^{\top}$를 trainable parameter $u \in \mathbb{R}^d$로 바꾸었습니다. 이 경우, 모든 query의 position마다 query vector가 동일하므로 각기 다른 단어에 가해지는 attention weight이 position에 상관없이 모두 동일하여야 합니다. 같은 원리로, (d)에서도 $\textbf{U}_i^{\top} \textbf{W}_{q}^{\top}$를 trainable parameter $v^{\top} \in \mathbb{R}^d$로 교체합니다.
- $\textbf{W}_{k,E}$와 $\textbf{W}_{k,R}$를 도입하였습니다. $\textbf{W}_{k,E}$는 content-based key vector, 그리고 $\textbf{W}_{k,R}$는 location-based key vector입니다.
Relative positional embedidng으로 인해 re-parameterization된 결과는, 각 항마다 아래와 같은 의미를 지닙니다.
- $(a)\ \textbf{E}_{x_i}^{\top} \textbf{W}_{q}^{\top}\textbf{W}_{k, E} \textbf{E}_{x_j} $ : content-based addressing
- $(b)\ \textbf{E}_{x_i}^{\top} \textbf{W}_{q}^{\top}\textbf{W}_{k, R} \textbf{R}_{i-j}^{\top} $ : content-dependent positional bias
- $(c)\ u^{\top}\textbf{W}_{k, E} \textbf{E}_{x_j}$ : global content bias
- $(d)\ v^{\top}\textbf{W}_{k, R} \textbf{R}_{i-j}^{\top}$ : global positinal bias
Relative positional embedding과 state reuse가 결합된 최종 Transformer-XL의 recurrence mechanism은 아래의 architecture를 갖게 됩니다.

Experiment
총 5가지 Dataset (WikiText-103, enwik8, text8, One Billion Word, Penn Treebank)에 대해 word-level과 charactor-level로 modeling하였을 때 아래와 같은 결과를 얻었습니다. 평가 metric은 word-level text dataset에 대해서는 PPL(perplexity), character-level text dataset에 대해서는 bpc (bits-per-character)를 사용하였습니다. PPL은 직역하자면 언어모델이 헷갈리는 정도입니다. 이는 모델이 language modeling을 할 때, 지금까지 봐왔던 token 다음에 올 token을 확률적으로 계산할 시 어느 정도의 보기를 가지고 고민하는가로 생각할 수 있습니다. bpc는 문자(character)를 encoding하는데 필요한 평균 비트 수입니다. 모델의 성능이 좋으면 각 character를 정확하게 예측해서 bit sequence가 짧아지기때문에 문자당 총 비트 수가 낮아지게 됩니다. 결국, PPL이든 bpc든 낮을수록 좋은 모델입니다.
Dataset & Result
아래 실험 결과에서 알 수 있듯이 모든 데이터셋에 대해서 Transformer-XL이 PPL/bpc가 가장 낮습니다.
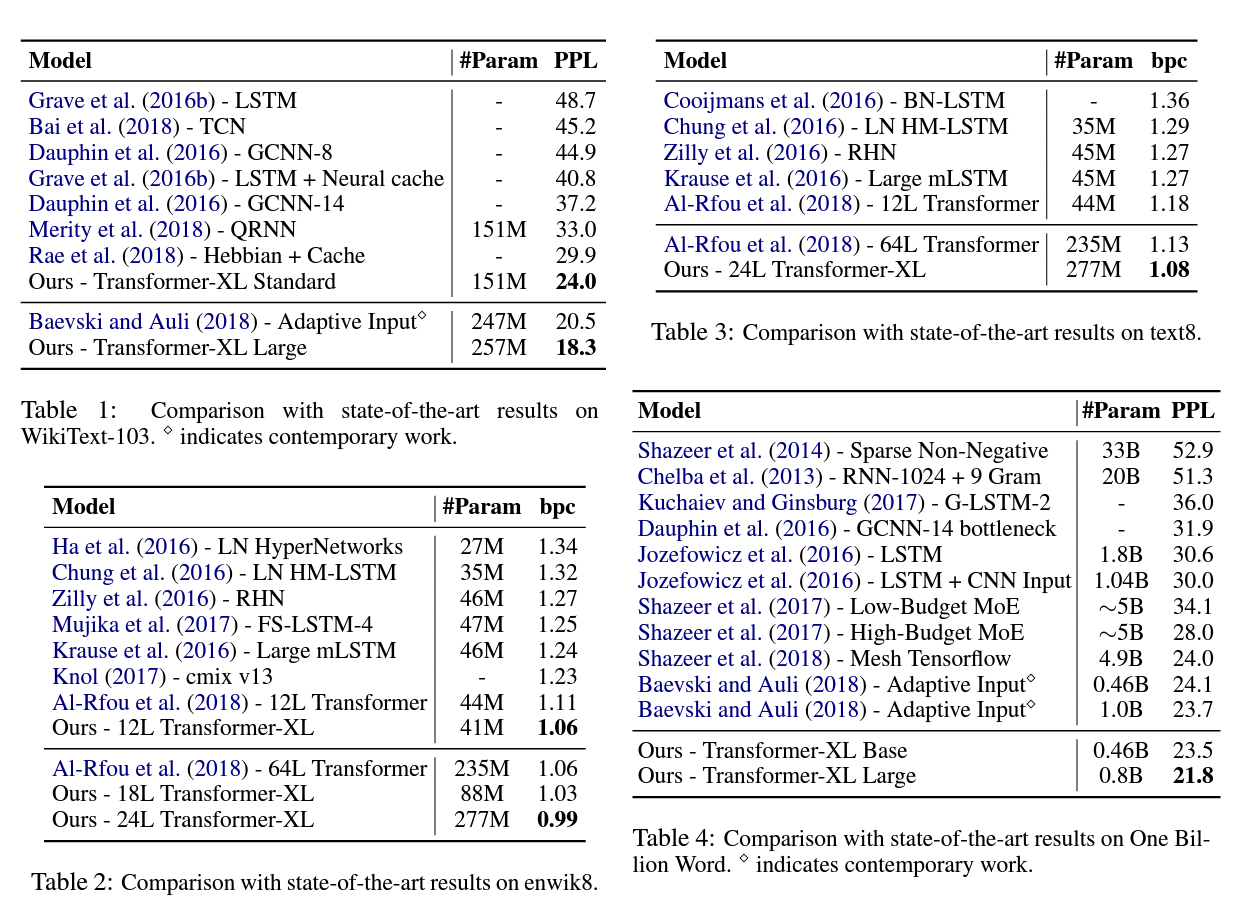
WikiText-103은 가용할 수 있는 가장 큰 word-level language model benchmark dataset입니다. Wikipedia의 article들로 dataset을 구성하였기때문에 long-term dependency modeling이 필요한 dataset입니다. 약 28K의 article들로부터 103M개의 token과 article당 평균 3.6K의 길이(token 개수)를 가지고 있습니다.
enwik8은 100M bytes의 가공되지 않은 Wikipedia text를 가진 dataset입니다. text8은 enwik8과 비슷하지만 100M의 가공된 Wikipedia character dataset이고, a부터 z까지의 소문자 charactor로만 전처리되었습니다. enwik8과 text8은 비슷한 데이터이므로 같은 hyper-parameter를 두고 학습하였다고 합니다.
One Bilion Word는 문장들이 shuffle되었기 때문에 long-term dependency를 가진 데이터셋은 아닙니다. 결과적으로, 이 데이터셋은 short-term dependency를 모델링하는 task가 되었으나 Transformer-XL이 long-term dependency에 특화된 모델임에도 다른 모델에 비해 outperform하는 결과를 얻었습니다. 즉, short-term dependency도 잘한다는 얘기입니다.
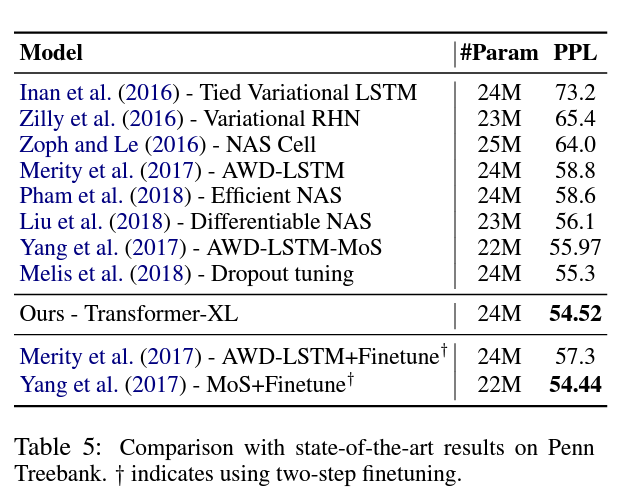
Penn Treebank dataset은 1M개의 token을 가진 비교적 적은 데이터셋임에도, Transformer-XL이 outperform하였습니다.
Ablation Study
Transformer-XL에 반영된 아이디어는 크게 2가지―1) Recurrence mechanism와 2) Relative positional encoding로, 이를 입증하기 위해서 아래와 같이 각 component를 포함/불포함시키어 효과성을 측정하였습니다.

- Encoding : Shaw et al. (2018)은 relative, Vaswani et al. (2017), Al-Rfou et al. (2018)은 absolute입니다.
- Loss : Full은 한 segment 내의 모든 position에 cross-entropy loss를 적용한 것이고, Half는 segment 내의 recent half position에만 cross-entropy를 적용한 것입니다.
- PPL init은 학습 시 모든 비교 모델의 길이를 동일하게 하였을 때의 PPL입니다.
- PPL best는 각 모델마다 optimal한 길이를 설정하였을 때의 PPL입니다.
- Atten Len은 이전 컬럼의 PPL best를 달성할 때, 가능한 가장 짧은 attention length가 몇 인지 체크한 것입니다. relative positional encodnig을 사용하면 attention length가 길수록 그에 비례하여 성능이 향상됩니다.
위 결과를 통해 알 수 있는 것은, absolute encoding이 오직 half loss일 때만 잘 working한다는 것입니다. 이는 half loss가 짧은 attention length를 가지는 position을 제외하였고, 이것이 generalization을 더 잘하도록 하였다는 분석입니다.
다음으로, 더 긴 context length를 모델링하는 것과 별개로 context fragment를 Transformer-XL가 잘 해결하는지만 보기 위해 long-term dependency가 적은 One Bilion Word dataset에서 실험하였습니다. 사견으로는, 이 실험의 의의를 생각해보면 context fragment를 근본적으로 해결하는 것은 단순히 이전 context를 고려하는 recurrence이지, longer context를 고려하면서 자연스럽게 해결되는 것이 아니다라는 가정에서 이 실험을 설계한 듯 합니다. 즉, recurrence mechanism의 효과성 (=짧은 context에서도 recurrence mechnism이 context fragment를 해결할 수 있는가?)만을 검증하고자 longer context를 고려해도 되지 않는 dataset에서 실험하였습니다.

1번째 row를 3번째 row와 비교하면 recurrence의 효과가, 2번째 row와 비교하면 relative positional encoding의 효과를 알 수 있겠습니다. 결과적으로, recurrence가 context fragment를 해결하는 효과가 있네요.