본 포스팅은 Semantics of the Unwritten: The Effect of End of Paragraph and Sequence Tokens on Text Generation with GPT2논문의 리뷰를 다루고 있습니다.
개인적 고찰은 파란색으로 작성하였습니다. 해당 내용에 대한 토론을 환영합니다 :)
Motivation
- Auto-regressive의 대표적인 모델인 GPT는 input sequence length에 제한이 있다.
- GPT가 주어진 문장 다음에 이어질 Token을 생성할 때, 알아서 generation stop을 할 수 없을까?
- GPT-2에서는 아쉽게도 이러한 기능을 직접적으로 구현할 수 없는데, 간접적으로 가능하도록 하는 방법이 있을 것 같다.
- 이상적으로 GPT가 적절하게 context를 배운다면, 알아서 <EOS> (End of sequence)을 out하고, 이 부분부터 자르면 되는 것이다.
- 본 논문은 이러한 문제의식으로부터 출발하여 찾게 된 논문이다.
Summary
- Text의 의미는 눈에 보이는 정보(단어)뿐만 아니라 눈에 보이지 않는 정보(문장 마침⎯맥락의 끝, 행간을 읽는다)들로도 중요하게 표현됨
- 이러한 not read information으로써, end-of-paragraph (EOP)와 end-of-sequence (EOS)가 generation quality에 영향을 미침
- Pre-trained GPT2가 fine-tuning시 end-of-paragraph를 generate하는 것을 학습하면 모델이 보다 연속성을 갖는 문장을 생성해 냄
- English story generation과 Chinese assay dataset에서 각각 좋은 성능을 보임
Introduction
- Large-pretrained model (LLM⎯BERT, GPT)가 등장하면서 많은 NLP task를 하나의 모델이 수행할 수 있게 됨
- 이 중에서도, GPT는 story, recipe, patent claim, new등과 같은 long-fluent text들을 생성해 낼 수 있었음
- 본 논문에서는 "언제 paragraph를 break하고 언제 sequence를 끝내야하는 지"가 텍스트의 의미를 더 풍부하게 한다고 가정하고 이에 대해 연구함
- 결론적으로 EOS, EOP를 학습한 모델이 더 좋은 generation task를 수행하였음
- 이를 통해 EOS뿐만 아니라 EOP도 모델 성능에 영향을 준다는 것을 밝힘
- 이러한 paragraph정보는 generation모델의 성능향상뿐만 아니라 end of text 자체도 generation할 수 있음(즉, 문장을 끊을 signal을 줄 수 있음)
- SEP/EOP/EOS는 pre-training단계에서 학습이 되어야(should be introduced) 더 좋은 결과를 얻을 수 있음
- 본 논문의 저자는 직접 Pre-trained GPT2를 구축하기에 resource가 많이 들기 때문에, pre-trained GPT2를 fine-tuning하는 단계에서 위 token들을 도입해야 했으나
- Pre-trained 단계에서부터 이를 학습하면 더 좋아질 것으로 예상하는 취지라고 보임
Backgroud
1. Tokenizer의 Special tokens
- LM(Language Model)의 Tokenizer에서 사용하는 special token이 여러가지 존재함
- BERT의 경우, 문장 시작을 알려줌과 동시에 classification의 softmax logit을 학습하는 [CLS] (classfication)
- 문장 끝과 다른 문장을 구분하기 위한 [SEP] (seperator)
- 고정된 길이의 input을 생성하기 위한 [PAD] (padding)
- 그리고 pretraining단계에서 필요한 [MASK]
- 이와는 다르게, GPT에서는 |endoftext| (end-of-sequence, EOS)만을 사용함
- 모델링하는 사람에 따라서 BOS token도 활용하기도 함 (begin-of-sequence)
- 또한, 역시 모델링하는 사람에 따라서 token을 다른 형태로 모델링하기도 함
- [BOS], [EOS]
- |beginoftext|, |endoftext|
- <s>, </s>
- BERT의 경우, 문장 시작을 알려줌과 동시에 classification의 softmax logit을 학습하는 [CLS] (classfication)
2. GPT의 implementational background
GPT는 fixed-length model이 아니어서(다만, 모델이 받을 수 있는 최대 sequence length는 존재함) input에 padding 붙여줄 필요가 없지만, generation은 모델이 허용하는 최대 길이까지만 할 수 있음
Auto-regressive model generation의 전제는 word sequence의 분포를 i.i.d(independent and identically distributed)가정에 의해 conditional word probability의 곱 형태로 나타낼수 있다는 것임

여기서, W0는 seed context라고 생각하면 되는데,
story generation task일 경우 story prompt(예를 들면, "영웅이 악당 물리치는 이야기해줘", "요정마을 이야기해줘" 등)를,
essay completion task에서는 essay 시작(도입)부분(예를 들면, "그 해 여름이었을까, 우리는~")을 말함
그리고, generated sequence길이 T는 EOS를 생섬함으로써 결정됨

Method
EOS는 input data 전체 끝에 붙는 token이라면 EOP는 중간중간엔 붙는 token임

paragraph가 \n(line-break)로 끝맺음되긴 하지만, 모든 \n가 paragraph seperator로써 기능을 하고 있지는 않음.
이에, EOP를 도입하여 확실한 paragraph seperator를 만들어 줌
본 논문에서 수행하고자하는 task dataset에서는 input에 paragraph 단위가 많지만, 현재 구분자로 사용되고 있는 \n가 제 기능을 온전히 하지 못하니, 확실한 seperator를 추가한 것으로 생각됨
Experiment
1. Dataset
- WritingPrompts : 300k human-written stories (short prompt - long story pair의 형태)
- ChineseEssay : 본 논문의 저자들이 직접 구축한 데이터셋. 초등학생들의 가족, 선생님에 관한 에세이들을 바탕으로 구축

2. Settings
- Model : OpenAI's GPT2-117M (12 layer, 117M parameters) / Chinese-GPT2
- Metrics
- W/T PPL : 모든 word/token에 대한 perplexity(PPL)
- W/T PPL(-) : EOS/EOP/SEP을 제외한 word/token에 대한 PPL
- EOS PPL : EOS에 대한 PPL (목적: 모델이 문장을 제대로 끝낼 수 있는지 보기 위함-1)
- EOS % : 생성된 문장 중 EOS로 끝맺은 문장의 비율 (목적: 모델이 문장을 제대로 끝낼 수 있는지 보기 위함-2)
- BLEU/DIST : EOS를 제외한 BLEU/distinct score
- Human Evaluation : 1) Topic relevance, 2) Fluency, 3) Ending quality, 4) Overall preference, 총 4가지의 항목을 가지고 4명의 native speaker들이 직접 generated text를 평가함
💡BLEU (Bilingual Evaluation Understudy)
(ref. BLEU: a Method for Automatic Evaluation of Machine Translation)
기계번역 task에서 PPL(perplexity)은 번역의 성능을 직접적으로 설명하기 어려움. 이에, 기계번역 성능을 실제 번역 문장과 기계 번역한 문장의 유사도를 측정하여 모델의 성능을 보고자 하는 것이 BLEU임
BLEU는,
1) n-gram기준 얼마나 겹치는 지 유사도를 확인함
: 1/2/3/4-gram을 이용하여 유사도를 체크
2) 같은 단어가 연속적으로 나와 성능이 과대측정되는 것을 방지함
: 기계번역 문장에서 반복적으로 단어가 나오더라도 이를 중복 산정하지 않음
3) 문장 길이의 penalty를 부여함
: 실제 번역 문장 대비 기계 번역 문장의 길이가 짧다면 penalty를 부여
3. Result
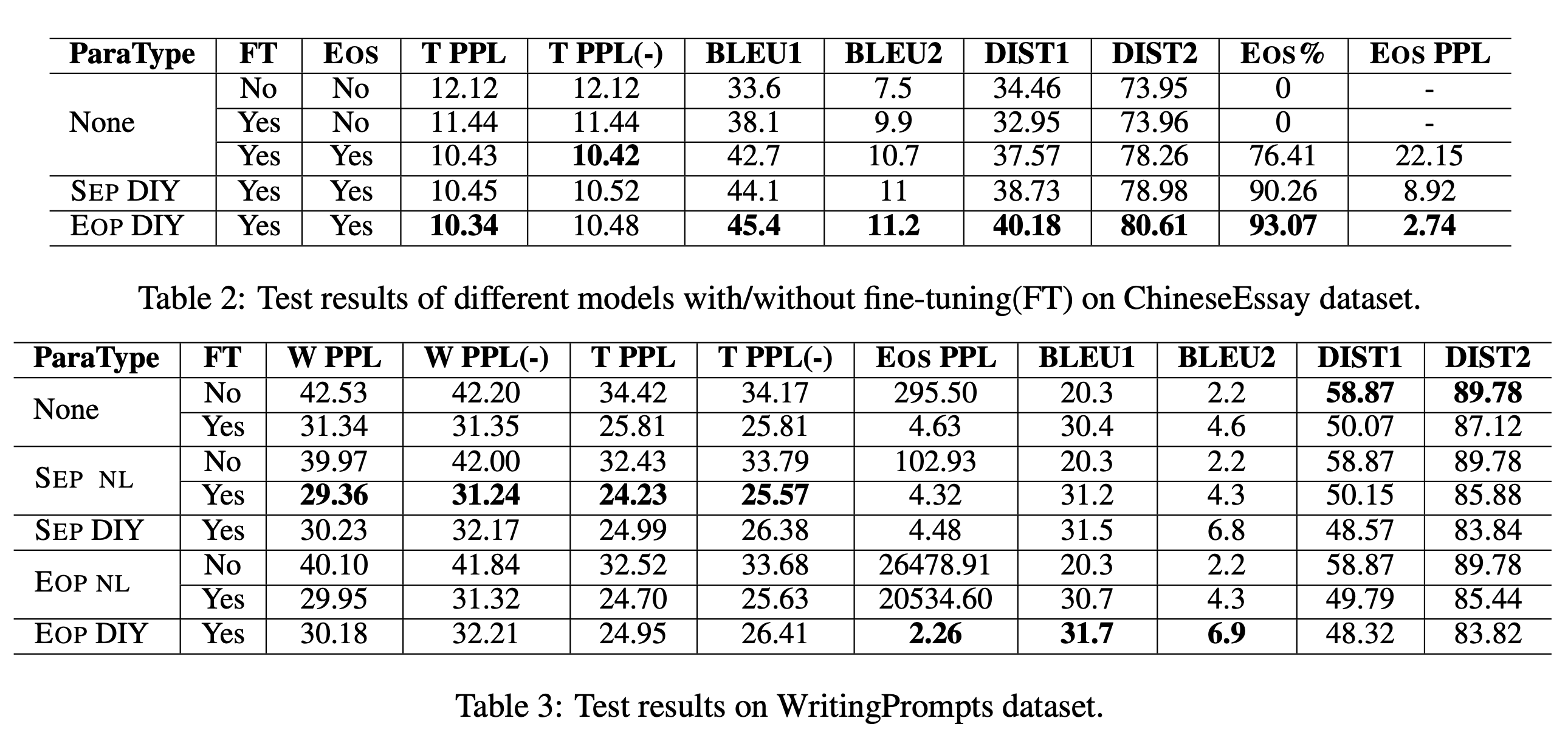
- Result table notation
- SEP NL, SEP DIY : paragraph를 NL/DIY라는 seperator로 concat함
- EOP NL, EOP DIY : paragraph를 concat하지 않고 끝에 NL/DIY라고 구분자만 넣어줌
- {~} DIY : 앞의 지시어 그 자체를 구분자로 사용함
- 예시
- SEP NL : paragraph를 \n으로 이어서(concat하여) 학습함
(input: paragraph_1 + '\n' + paragraph_2 + '\n' + paragraph_3) - EOP DIY : paragraph를 끝에만 EOP token을 넣어서 학습한 모델
(input: paragraph + [EOP])
- SEP NL : paragraph를 \n으로 이어서(concat하여) 학습함
- ChineseEssay
- paragraph 끝에 EOP token을 달아 준 데이터로 학습한 모델이 가장 outperform함
- None에 비해 EOP DIY가 EOS % 지표에서 상승한 것을 통해, 모델이 EOS로 generation을 끝맺는 법을 잘 학습했다고 볼 수 있음
- WritingPrompt
- English GPT-2는 EOS와 \n으로 pretrain되어 있음 → 이를 fine-tuning함
- 결과적으로는 SEP NL모델이 가장 outperform함
- paragraph information없는 모델보다 SEP/EOP가 포함된 모델이 전반적으로 성능이 좋음
- EOS PPL이 낮을수록 end-of-sequence, 즉, input의 마지막을 잘 끝낸다는 것 (prediction of EOS)
- EOP DIY모델이 가장 낮으며, paragraph information이 없는 모델보다 SEP/EOP로 학습한 모델이 전반적으로 EOS PPL이 낮음
Conclusion
- EOP와 EOS information이 문장 생성에 더 좋은 성능을 보임
- 단순히, token을 generation하는 순서도 중요하지만 context의 구분을 알려주는 것이 문장 생성에도 도움이 됨
- input의 context구분이 필요하다면, 이를 학습시키자 → 성능이 좋아짐
- EOS가 input sequence의 마지막을 지시하고, 중간 context마다 끊어갈 필요가 있을 때(paragraph단위로) EOP가 이를 지시하도록 input을 구성하는 것이 유효
'AI > NLP' 카테고리의 다른 글
| Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks (0) | 2024.01.12 |
|---|---|
| Evaluation Metrics for Language Models (0) | 2024.01.10 |
| Open Source GPT-3 (GPT-Neo, GPT-J) (0) | 2024.01.08 |
| Transformer-based Seq2Seq: Leveraging Pre-trained Checkpoints for Sequence Generation Task (0) | 2022.07.07 |
| GPT-2 : Language Models are Unsupervised Multitask Learners (0) | 2022.06.29 |



